


はじめに
「Amazon Kinesis Data Analytics (以下KDA) サポート終了」の報を受け、本番稼働中のアプリケーション移行で悩んでいる方も多いのではないでしょうか。
特に、既に本番環境で稼働しているリアルタイムストリーム処理を「サービスを停止させず」、かつ「他の既存システムに影響を与えず」に移行するのは、非常に難しいことだと思います。
今回、私たちが担当したプロジェクトにおいて、まさに上記の状況におかれ、本番稼働中の KDA から Amazon Managed Service for Apache Flink(以下Flink) への移行プロジェクトを実施しました。
本記事では、プロジェクトで最も重要だった以下の2点に焦点を当て、私たちが実践した内容について記載します。
- 既存システムへの影響を最小化する「アーキテクチャ設計」
- 本番システムを安全に切り替えるための「2段階リリース戦略」
KDAからFlinkへの移行方法を検討している方や本番稼働中のシステム内の一部サービスを安全に切り替える方法を探している方はぜひご一読ください。
また、本記事では以下については取り扱いませんのでご注意ください。
- AWS各サービスの基本的な知識
- KDAおよびFlinkの実装処理の詳細内容、及びソースコード
現行システムの概要と移行の背景
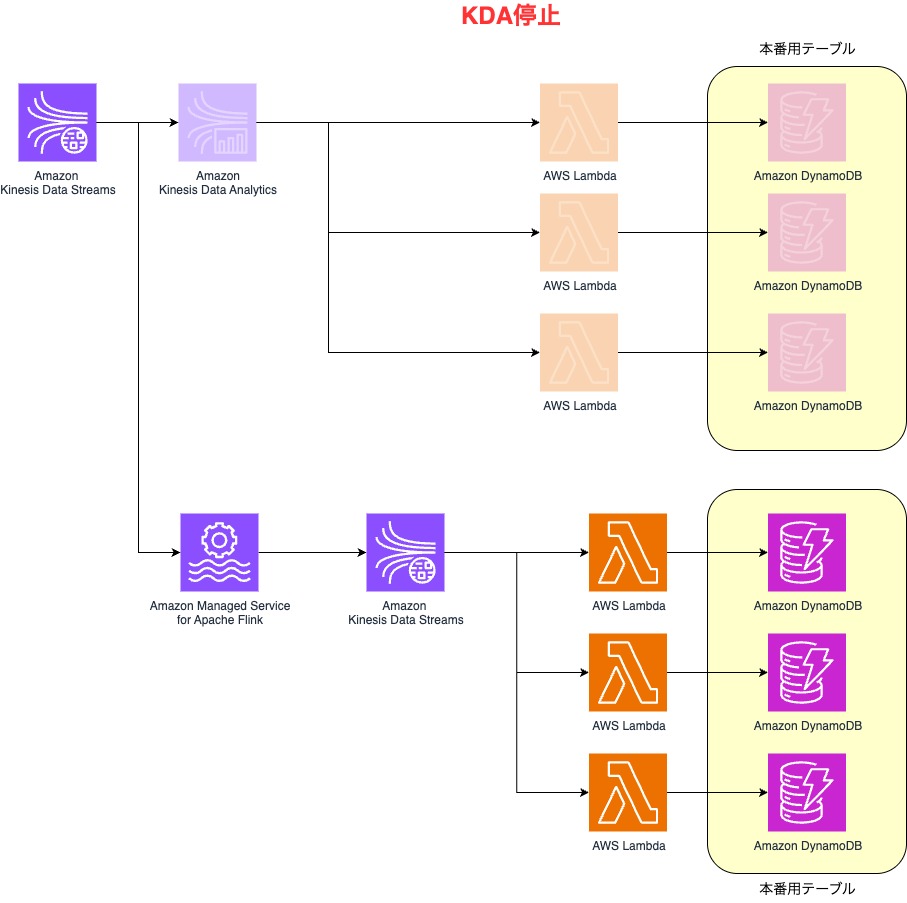
1分間に最大数十万レコードの様々なデータが並行してクラウドに送信されているシステムがあります。こちらは現在、実際に本番稼働されていて非常に多くのデータが流れてきている状態です。それらの送信されたデータをリアルタイムに集計処理をし、DBに保存する必要があるため以下のアーキテクチャを実装していました。
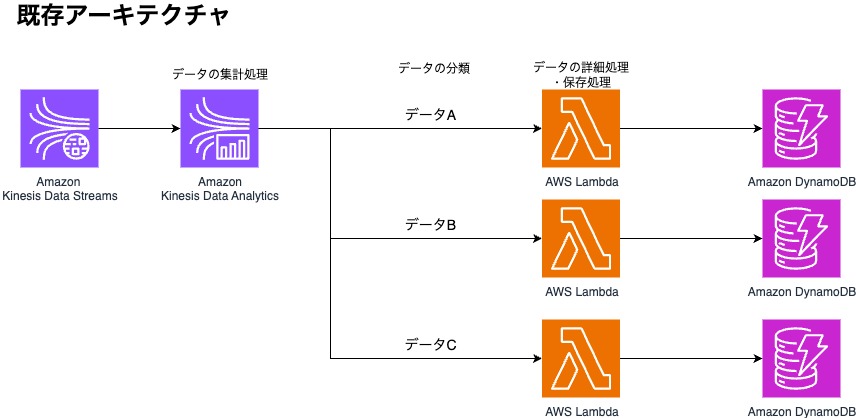
上記のアーキテクチャで長年稼働を続けていましたが、AWSからKDAがサポート終了するという案内があり、2026年1月までにシステムの改修が必要となりました。この案内の中に「アプリケーションを Amazon Managed Service for Apache Flink または Amazon Managed Service for Apache Flink Studio に移行することをお勧めします。」という記載があったことからFlinkへ移行することとしました。しかし、上記のアーキテクチャは本番稼働しているため、サービスを停止させず(あるいは停止時間をできるだけ短く)、かつ他の処理に影響を与えないように移行作業をする必要がありました。
移行の際の課題:アーキテクチャの見直し
現行のアーキテクチャではKDA内でデータの集計処理だけではなく、データの種類に応じて後続のLambdaの振分け処理も実施していました。
今回、Flinkへ移行するとなった際、スキルセットの関係でFlinkアプリをpythonで実装することとしたのですが、FlinkアプリでLambdaの振分け処理をするのは大変複雑で問題が発生した際の対応も困難になると判断したため、アーキテクチャを見直す必要が出てきました。
この課題を解決するために、アーキテクチャを以下の構成にしました。
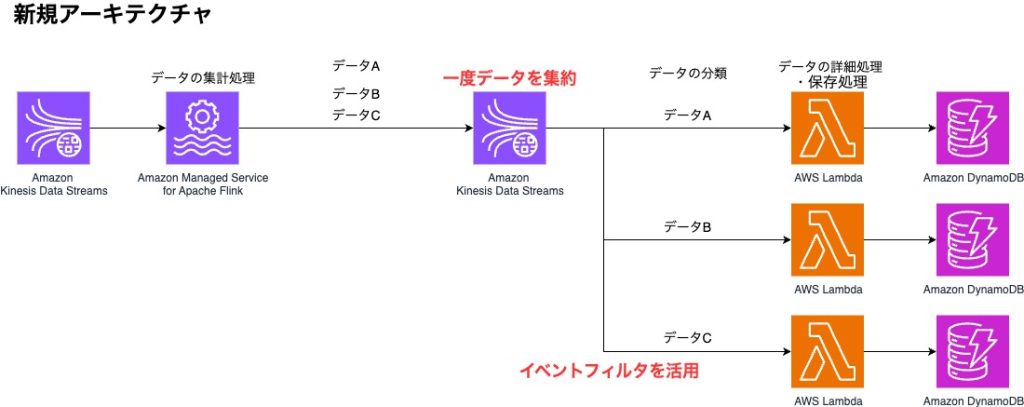
ポイント:データの振分け処理の責任箇所の変更
移行前のようにFlinkアプリ内でデータの振分け処理をするのをやめ、Flinkアプリでは集計のみに専念させ、すべてのデータをKinesis Data Streams(以下KDS)へ出力するようにしました。
データの振分け処理自体は後続のAWS Lambdaの機能であるイベントフィルタを活用することで、データの種類によって実行するLambdaを振り分けることを実現しました。
後続のLambdaのトリガーとなるイベントソースが変更になったためLambdaに渡されるevent内容に一部変更が生じ、後続のLamba関数に軽微な修正が必要となりましたが、既存の詳細ロジックの修正は実施せず対応することができました。
発生したトレードオフ:レイテンシーの増加
Flinkアプリの並行処理数や追加したKDSのシャード数を調整することで、追加したKDSにデータが滞留することはなくなりました。しかし、移行前のアーキテクチャからKDSを追加したことにより、データがDynamoDBに保存されるまでに数十〜数百msの遅れが生じるようになりました。現状ユーザーへ大きな影響が発生していないことから許容範囲内としていますが、この点は今回のアーキテクチャにおける妥協点といえます。
安全でスムーズな移行を実現する「リリース計画」
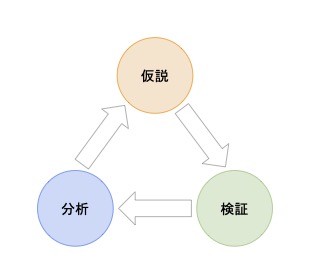
新しいアーキテクチャを作成できても、それをどのようにして安全に・できるだけシステムを停めずにリリースするかが重要です。特に、本番稼働しているためデータの欠損は絶対にあってはいけません。Flinkアプリの起動モードや作業順を変えるなど、どのような手順にすればデータの欠損なく移行作業ができるのかいくつか仮説を立てました。仮説を元に検証し、検証結果をチームに展開し、結果を分析する、という作業を繰り返すことで安全かつスムーズにリリース作業ができる方法を確立しました。
二段階のリリース作業
安全にリリース作業をするために以下の2回に分けてリリース作業を実施しました。
- 1回目:並行稼働によるデータ整合性と負荷の検証
- 2回目:KDAを停止し、Flinkへの完全移行
一度目のリリース:並行稼働
一度目のリリース作業では現行のKDAを動かした状態で、新基盤であるFlinkを本番環境で動作したときの検証作業をします。
これにより、Flinkに移行しても本番のシステムで問題なく稼働できることの確証を得ることができます。
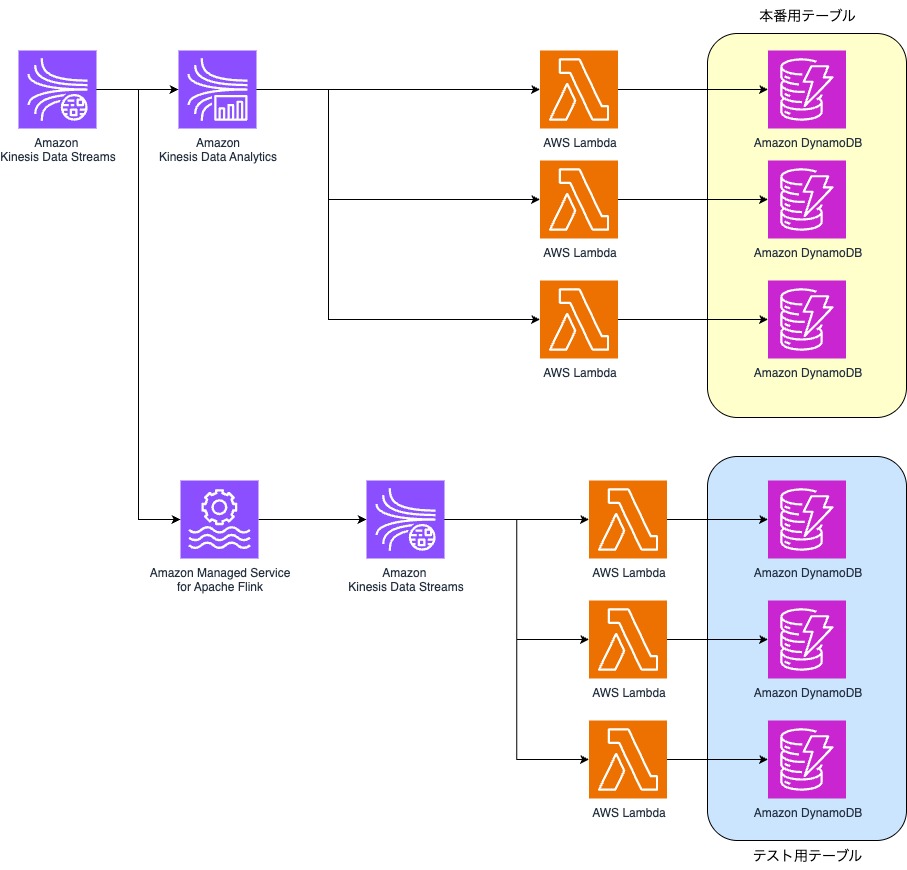
検証中はFlinkから流れるデータの保存先をテスト用のテーブルにします。
ここで本番用のテーブルのデータと比較することで以下のことを検証することができました。
- データに欠損がないか
- データの集計結果に誤りがないか
- KDA利用時と比較して、レイテンシーが許容範囲内に収まっているか
- FlinkやKDS等、各サービスが実際の負荷に耐えられるか
1週間稼働し、上記項目を中心に監視することで「Flinkへ移行しても問題ない」という確証を得ることができました。
二度目のリリース:スムーズなFlink移行
一度目のリリースでFlinkの構成に問題ないことが確認できたので、二度目のリリースでは実際にFlinkアプリを本番のシステムに組み替えました。
Flinkアプリの向き先をテスト用テーブルから本番テーブルに変更し、KDAのアプリケーションを停止します。
向き先の変更からKDAのアプリケーションの停止まで一時的に二重にテーブルへの書き込みが発生するためDynamoDBの書き込みキャパシティを増強する必要があることに注意が必要です。
これらのステップを踏むことで安全かつスムーズなFlink移行のリリース作業をすることができました。
綿密なフェイルバック計画
本番稼働しているシステムの移行計画ではフェイルバック計画を立てることも重要です。
検証期間中は問題がなくても、二度目のリリースでKDAを停止した後に問題が発生した場合に
データの欠損なく、遅延を少なく元の構成に戻すための手段を綿密にシミュレーションしました。
KDAアプリケーションは一般的にアプリケーションを起動すると起動後の最新データから処理するようになります。
しかし、そうするとKDAを停止してトラブルが発生してからKDAを再開するまでの期間のデータが欠損してしまいます。
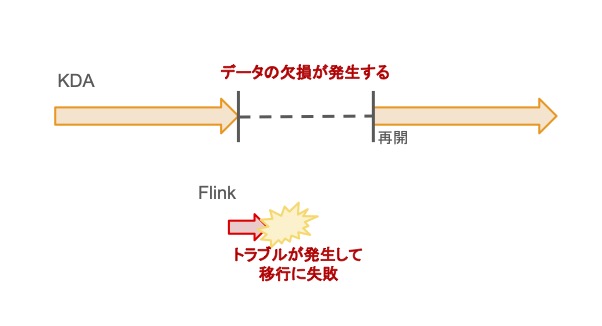
この間のデータ欠損を防ぐためにフェイルバック計画ではアプリの起動コマンドをあらかじめスクリプト化しておくことでKDA停止時点からのデータを取得できる状態を用意しました。
事前に考えられる範囲でのトラブルを想定し、その際の対処方法を準備することで作業側の心理的にも安心してリリースに挑むことができました。
最後に
本記事では本番稼働しているシステムで利用しているサービスが終了するという回避できない、かつ期限があるKDAからFlinkへのサービス移行対応について記載しました。
本番稼働しているKDAからFlinkのサービス移行は単にアプリを修正するだけではなく、多くの課題に突き当たりました。
今回、本番稼働しているサービスの移行作業で必要なことは以下であることを学びました。
- 他の処理に影響を与えない、かつ保守性を保つアーキテクチャを考えること
- 並行稼働を活用して、安全かつスムーズなリリース計画を考えること
- トラブルが発生した時にデータ欠損が生じないフェイルバック計画を考えること
上記を深く考慮することでトラブルなく移行作業が実施できたのではないかと考えます。
これは今回のFlinkへの移行だけに限らず、他のサービスの移行作業でも同じことだと思います。
本番稼働しているシステムを、安全かつスムーズに移行をしなければいけない状況にある方々の参考になれば幸いです。
AWS移行やストリーム処理基盤の構築について、ぜひお気軽にKYOSOへお問い合わせください。
投稿者プロフィール

-
2017年新卒入社。
入社当時からAWSを用いた開発をしています。
その中でも、サーバーレス構成をメインにしたアーキテクチャ設計から構築・運用に従事しています。
新たに得た経験や技術を積極的に共有することを心がけています。
