


なぜ AWS Glue の環境構築は「大変」なのか
AWS Glue(PySpark)でジョブを開発するとき、一番の障壁となるのは、ビジネスロジックそのものではなくローカル実行環境の準備ではないでしょうか。
- Spark の環境を整えるだけで時間がかかる
- 依存ライブラリやバージョン差異でローカル実行が安定しない
- 結局、コードを書いてはデプロイし、数分待ってログを確認する……という往復に戻ってしまう
実は私自身、以前は「ローカルで書いたコードを Glue の Web 画面に貼り付け、実行ボタンを押し、数分待ってようやくログを確認する」という属人的かつ原始的な手法で開発を進めていました。
この手法は一時的な回避策としては成立しますが、実案件の複雑なロジックを組むとなると、このサイクルはあまりにも非効率で「このままでは実際の開発現場では通用しない」と痛感したのが、今回の環境構築に乗り出した一番のきっかけです。
本記事では、AWS 公式の Glue Docker イメージと LocalStack を組み合わせて、Glue ジョブをローカルで高速に検証できる開発環境を構築する方法を紹介します。
この構成を使うことで、次のような開発サイクルを作れるようになります。
- クラウドへ都度デプロイせずに、手元で ETL ロジックをすばやく確認できる
- LocalStack 上の S3 を使って、入出力込みのテストを安全に繰り返せる
- pytest を使って、Glue ジョブの動作をローカルで検証できる
- Dev Containers によって、チーム内で同じ実行環境を共有しやすくなる
「Glue 開発はデプロイして試すもの」という前提を捨て、実装・テスト・検証をローカルで回せる環境を作っていきましょう。
対象読者
本記事は、次のような方を対象としています。
- AWS Glue の基本的な役割を理解しており、実際にジョブ開発を進めたい方
- PySpark / Glue ジョブを使ったデータ処理の流れを把握している方
- AWS 上に毎回デプロイして試す開発サイクルに、もどかしさを感じている方
- Glue ジョブをローカルで検証できる環境を作りたい方
- pytestを使って ETL ロジックをテストしやすい形にしたい方
- VS Code の基本機能や Dev Containers の利用イメージを持っている方
本記事で取り扱わないこと
本記事の主眼は、AWS Glue のローカル開発環境を構築し、実装とテストを高速に回せる状態を作ることです。
そのため、以下の内容は扱いません。
- AWS Glue の基本概念そのものの解説
- PySpark の文法やデータ処理の基礎
- pytest の基本的な書き方やフィクスチャ入門
- VS Code / Dev Containers の基本操作
- Spark や Hadoop の内部実装の詳細
AWS Glue をローカル完結で開発するメリット
Glue ジョブをクラウド上で直接開発するスタイルから離れることで、開発体験は大きく変わります。
特に大きいのは、実装スピード・検証しやすさ・再現性の3点です。
フィードバックループが圧倒的に速くなる
クラウド上でのジョブ実行は、コード修正以外にもデプロイや起動待ちが発生します。
一方、ローカル環境でテストできれば、確認にかかる時間は数分から数秒まで縮まります。
この差は単なる待ち時間の削減ではありません。
試行錯誤の回数が増えることで、変換ロジックの精度や例外ケースへの対応力が大きく上がります。
AWS リソースの影響を懸念せず試行錯誤できる
LocalStack を使えば、S3 バケットの作成・削除やテストデータの投入をローカルで何度でも繰り返せます。
本番や検証用 AWS 環境を汚す心配がないため、べき等性を意識したテストもやりやすくなります。
チーム全員が同じ環境をすぐ再現できる
Dev Containers を使えば、ローカルの個別設定に依存しない環境を配布できます。
Spark や Glue のように環境構築の難易度が高い技術でも、「VS Code で開くだけで動く」状態に持ち込めるのは大きなメリットです。
テストしやすい構成をそのまま実務に持ち込める
ローカルで Glue ジョブを実行できるだけでなく、pytest を組み合わせることで、ETL ロジックや入出力の検証まで含めた開発サイクルを回せるようになります。
その結果、“動いたら終わり”ではなく、“繰り返し確認できる構成” を作りやすくなります。
Docker 公式コンテナ + LocalStack による AWS Glue 開発環境の構築手順
今回のローカル開発環境は、主に次の 2 つで構成します。
- AWS Glue 公式 Docker イメージ
Glue / Spark の実行環境をローカル上に再現するために利用します。 - LocalStack
S3 などの AWS サービスをローカルでエミュレートするために利用します。
この 2 つを組み合わせることで、Glue ジョブの実行基盤と、ジョブがアクセスする AWS リソースの両方をローカルに用意できます。
その結果、クラウドへ都度デプロイしなくても、ETL ロジックをできるだけ本番に近い形で検証できるようになります。
また、開発者は VS Code から Dev Containers 経由で Glue コンテナに入り、コード編集・テスト実行・デバッグを一貫して行えます。
つまりこの構成は、単に「Glue をローカルで動かす」だけではなく、普段の開発体験そのものをローカル完結型に寄せるための土台でもあります。
補足
AWS Glue の公式コンテナイメージは、環境によっては 7GB 前後 と比較的大きめです。
初回セットアップ時は、Docker イメージの取得時間だけでなく、ローカルのディスク空き容量にも注意してください。
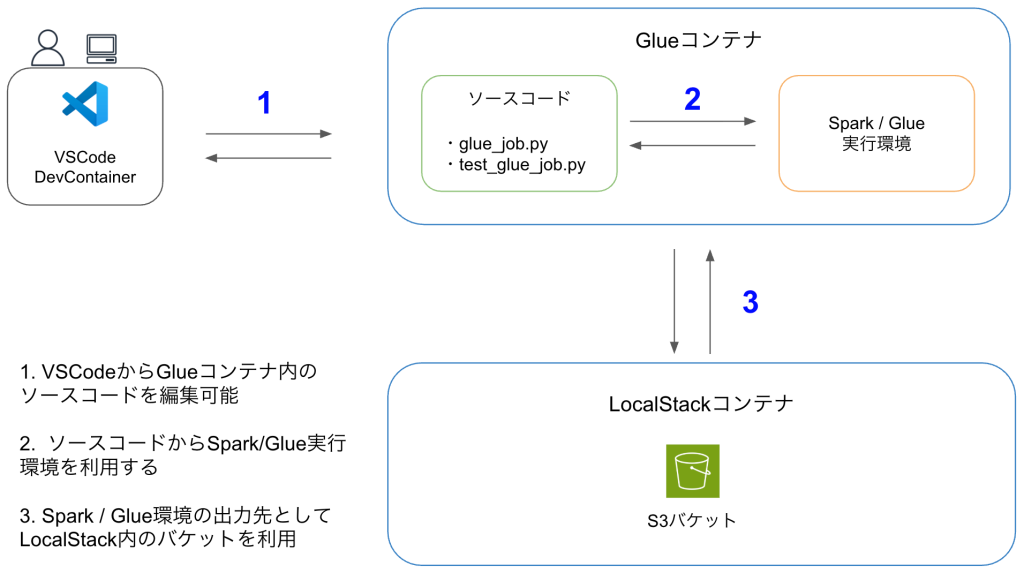
構成イメージ
関係性を以下のように整理しました。
- VS Code
開発者がコードを書く入口。Dev Containers 経由で Glue コンテナに接続する - Glue コンテナ
PySpark / Glue ジョブを実行するメインの開発環境 - LocalStack
Glue ジョブの入出力先となる S3 をローカルで模擬する - pytest
Glue コンテナ内で ETL ロジックや入出力結果を検証する
ディレクトリ構成
glue-local-dev/
├── .devcontainer/
│ ├── devcontainer.json # コンテナの起動・VS Code連携設定
│ └── docker-compose.yml # Glue(Spark) と LocalStack(S3) の定義
│ └── Dockerfile # 公式イメージのカスタマイズ用
├── src/
│ └── glue_job.py # ETL本体
├── tests/
│ ├── conftest.py # GlueContext初期化
│ ├── test_glue_job.py # テストコード本体
│ └── fixtures/
│ └── input_data.json # テスト用データ
└── requirements.txt # boto3, pytest など
コンテナ定義
VS Code の Dev Containers 機能を使う前提で構成します。
Apple Silicon 環境でも動かしやすいよう、platform も明示します。
devcontainer.json
{
"name": "AWS Glue Local Dev",
"dockerComposeFile": "docker-compose.yml",
"service": "glue",
"workspaceFolder": "/home/glue_user/workspace",
"postCreateCommand": "pip install -r requirements.txt",
"customizations": {
"vscode": {
"extensions": [
"ms-python.python",
"ms-python.pylance"
],
"settings": {
"python.defaultInterpreterPath": "/usr/bin/python3",
"python.testing.pytestEnabled": true,
"python.testing.pytestArgs": ["tests"]
}
}
}
}
docker-compose.yml
version: "3.8"
services:
glue:
platform: linux/amd64
build:
context: .
dockerfile: Dockerfile
container_name: glue_local
command: -c "sleep infinity"
volumes:
- ..:/home/glue_user/workspace/
environment:
- AWS_ACCESS_KEY_ID=test
- AWS_SECRET_ACCESS_KEY=test
- AWS_DEFAULT_REGION=ap-northeast-1
- S3_ENDPOINT_URL=http://localstack:4566
depends_on:
- localstack
localstack:
image: localstack/localstack:4.14.0
container_name: localstack_glue
environment:
- SERVICES=s3
- DEFAULT_REGION=ap-northeast-1Dockerfile
FROM --platform=linux/amd64 amazon/aws-glue-libs:5
WORKDIR /home/glue_user/workspaceここでは Glue 公式イメージをそのままベースにしています。
まずは最小構成で始め、必要に応じて requirements.txt のインストールやツール類の追加を行うのがおすすめです。
【実践】 JSONL を Parquet 変換し S3 へパーティション保存する
今回のサンプルでは、JSONL 形式のユーザーデータを読み込み、registered_date をもとに year / month パーティションを付与して Parquet 出力します。
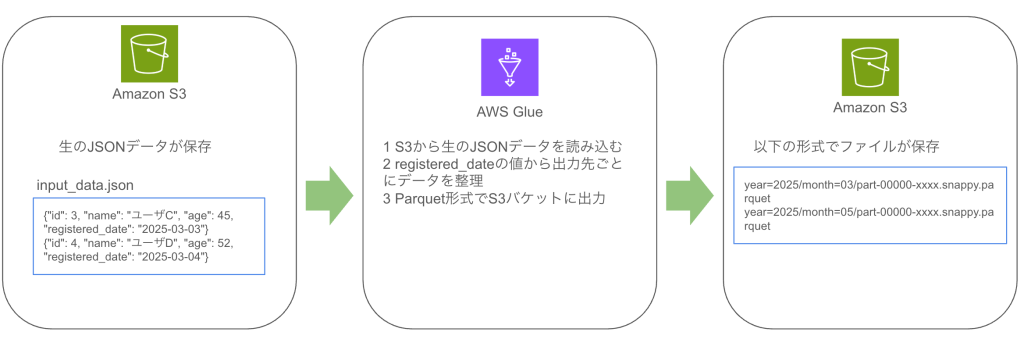
入力データ
tests/fixtures/input_data.json(一部抜粋)
{"id": 1, "name": "ユーザA", "age": 34, "registered_date": "2025-03-01"}
{"id": 2, "name": "ユーザB", "age": 27, "registered_date": "2025-03-02"}
{"id": 3, "name": "ユーザC", "age": 45, "registered_date": "2025-03-03"}
{"id": 4, "name": "ユーザD", "age": 52, "registered_date": "2025-03-04"}出力イメージ
output/year=2025/month=03/part-00000-xxxx.snappy.parquetこのような「日付由来のパーティション分割」は、Glue ジョブでも非常によくあるパターンです。
そのため、単に動くだけでなく、ロジックをテストしやすい構造にすることが重要になります。
LocalStack を利用した Glue ジョブ実装の勘所とコード解説
変換ロジックを分離する
Glue ジョブを書き始めると、入出力処理と変換処理をひとつの関数に詰め込む傾向があります。
ただしその構成だと、テスト対象が大きくなり、検証も困難になります。
そこで本記事では、ETL のコアロジックを transform_logic として分離します。
これにより、Glue 固有の入出力と、純粋な変換ロジックを切り分けて考えられるようになります。
src/glue_job.py
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql import functions as F
def transform_logic(df):
"""ETLコアロジック:データの型変換とパーティション列の生成"""
return (
df.withColumn("reg_dt", F.to_date(F.col("registered_date")))
.withColumn("year", F.year(F.col("reg_dt")))
.withColumn("month", F.format_string("%02d", F.month(F.col("reg_dt"))))
.filter(F.col("year").isNotNull())
)
def run_etl(glue_context, args):
job = Job(glue_context)
job.init(args["JOB_NAME"], args)
input_dyf = glue_context.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={"paths": [args["INPUT_PATH"]]},
format="json",
)
transformed_df = transform_logic(input_dyf.toDF())
output_dyf = DynamicFrame.fromDF(transformed_df, glue_context, "output_dyf")
glue_context.write_dynamic_frame.from_options(
frame=output_dyf,
connection_type="s3",
connection_options={
"path": args["OUTPUT_PATH"],
"partitionKeys": ["year", "month"],
},
format="parquet",
)
job.commit()
if __name__ == "__main__":
args = getResolvedOptions(sys.argv, ["JOB_NAME", "INPUT_PATH", "OUTPUT_PATH"])
sc = SparkContext()
glue_context = GlueContext(sc)
run_etl(glue_context, args)
この実装で押さえたい点
- transform_logic を独立させることで、変換処理の責務が明確になる
- run_etl は「入力・変換・出力」のオーケストレーションに専念できる
- 将来的にロジック追加や単体テストを行う際も、影響範囲を小さく保てる
実務では、Glue ジョブが大きくなるほど、この分離が効果を発揮します。
テスト用の GlueContext を共通化する
テストコード側では、毎回 GlueContext や SparkContext の初期化を書くと冗長になります。
そこで conftest.py に共通フィクスチャとして切り出します。
tests/conftest.py
import os
import pytest
from pyspark import SparkConf
from pyspark.context import SparkContext
from awsglue.context import GlueContext
S3_ENDPOINT = os.getenv("S3_ENDPOINT_URL", "http://localstack:4566")
@pytest.fixture(scope="function")
def glue_context():
"""
関数スコープの GlueContext フィクスチャ。
SparkContext を LocalStack S3 エンドポイントへ向けて初期化し、
テスト関数終了時に停止する。
"""
conf = SparkConf()
conf.set("spark.master", "local[*]")
conf.set("spark.app.name", "GlueLocalTest")
# LocalStack S3 エンドポイント設定
conf.set("spark.hadoop.fs.s3a.endpoint", S3_ENDPOINT)
conf.set("spark.hadoop.fs.s3a.access.key", "test")
conf.set("spark.hadoop.fs.s3a.secret.key", "test")
conf.set("spark.hadoop.fs.s3a.path.style.access", "true")
conf.set("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
# s3:// / s3n:// スキームも S3AFileSystem 経由で LocalStack へルーティング
conf.set("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
conf.set("spark.hadoop.fs.s3n.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
glue_ctx = GlueContext(sc)
yield glue_ctx
sc.stop()
ここで重要なのは、Spark から見た S3 の接続先を LocalStack に向けていることです。
ローカルテストがうまく動かない原因の多くは、このあたりの設定漏れにあります。
pytest で ETL の入出力を検証する
次に、S3 バケットの準備からジョブ実行、結果検証までを pytest でまとめます。
tests/test_glue_job.py
import pytest
import boto3
from botocore.exceptions import ClientError
import os
from src.glue_job import run_etl
S3_ENDPOINT = os.getenv("S3_ENDPOINT_URL", "http://localstack:4566")
@pytest.fixture
def s3_lifecycle():
"""テスト実行ごとにS3環境を準備・削除する"""
s3 = boto3.resource("s3", endpoint_url=S3_ENDPOINT, region_name="ap-northeast-1")
bucket_name = "local-test-bucket"
bucket = s3.Bucket(bucket_name)
try:
bucket.load()
bucket.objects.all().delete()
bucket.delete()
except ClientError as e:
if e.response["Error"]["Code"] not in ("NoSuchBucket", "404"):
raise
bucket.create(CreateBucketConfiguration={"LocationConstraint": "ap-northeast-1"})
bucket.upload_file("tests/fixtures/input_data.json", "input/raw.json")
yield bucket_name
bucket.objects.all().delete()
bucket.delete()
def test_etl_output_consistency(s3_lifecycle, glue_context):
bucket_name = s3_lifecycle
output_base = f"s3://{bucket_name}/output/"
args = {
"JOB_NAME": "test",
"INPUT_PATH": f"s3://{bucket_name}/input/",
"OUTPUT_PATH": output_base,
}
run_etl(glue_context, args)
# 2025年3月分のパスを直接指定して件数を検証
path_2025 = f"{output_base}year=2025/month=03/"
df_2025 = glue_context.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={"paths": [path_2025]},
format="parquet",
).toDF()
assert df_2025.count() == 20
print("\n=== year=2025/month=03 先頭データ ===")
for row in df_2025.limit(5).collect():
print(row)
このテストで確認していること
このテストは、単に関数が落ちないことではなく、以下をまとめて検証しています。
- 入力データを S3 から読み込めること
- ETL が期待通りに実行されること
- 指定したパーティション配下に Parquet が出力されること
- 出力データ件数が想定通りであること
つまり、Glue ジョブの実行経路をかなり実践的な形で確認できるというわけです。
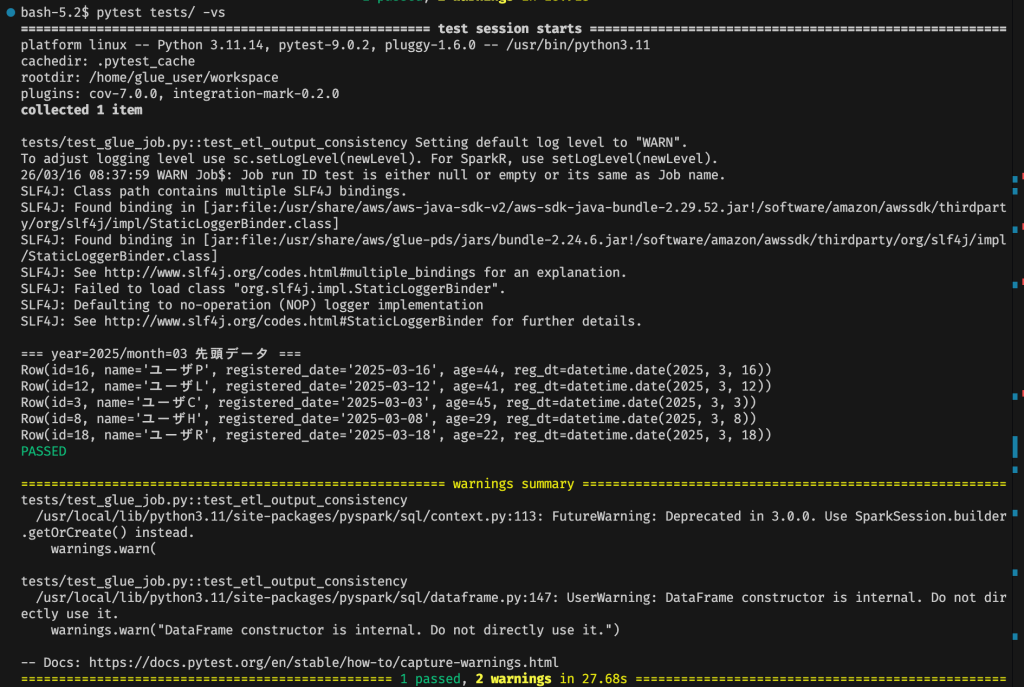
実際の実行画面は以下のとおりです。
VS Code の Dev Containers 内のターミナルで pytest を実行しており、テスト結果やログ出力をその場で確認できます。
普段コードを書いているのと同じ環境のまま、実装・テスト・動作確認までを一気通貫で進められるため、開発効率を大きく高められます。
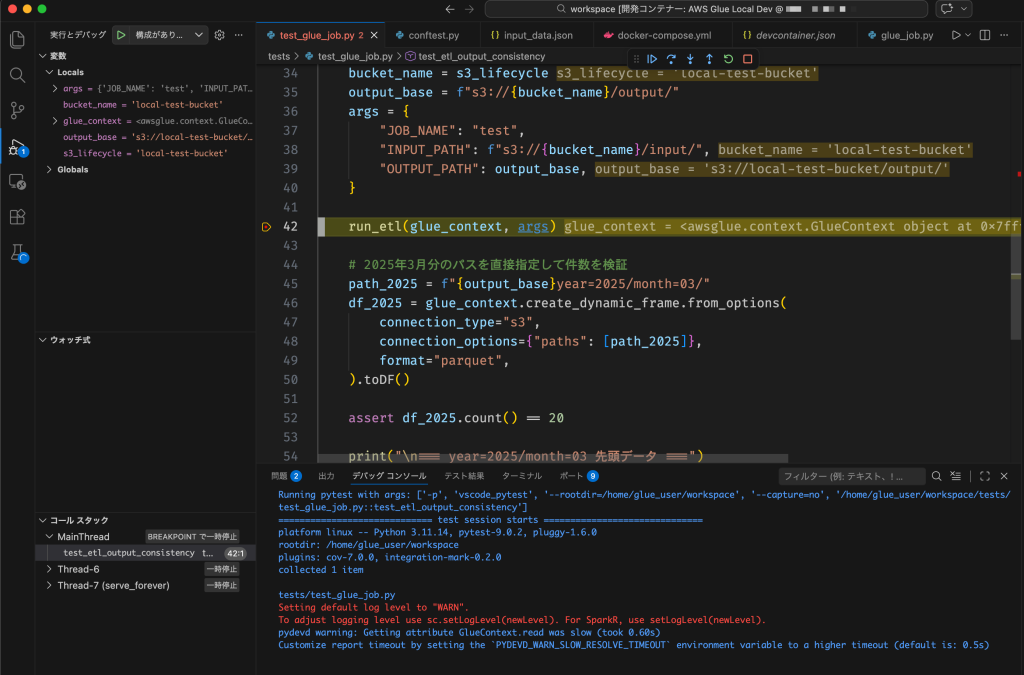
また、VSCodeを利用したデバッグ実行も可能です。
ローカル Glue 開発で気をつけるべきポイント
Glue のローカル実行は便利ですが、いくつか気をつけるべきポイントがあります。
先に知っておくだけでも、トラブルシュートにかかる時間をかなり減らせます。
- S3 Endpoint
コンテナ内から LocalStack に接続する場合、localhostではなく Docker Compose のサービス名であるhttp://localstack:4566を使います。 - リージョン制約
ap-northeast-1などを使う場合、bucket.create()の際にLocationConstraintを明示しないと正しく動作しないことがあります。 - テストの後始末
バケットやオブジェクトの削除処理を fixture に含めておくと、テスト再実行時に前回の実行結果を引きずりにくくなります。
特に、「動かない理由がコードではなく環境差分だった」という状況は消耗しやすいため、このあたりは最初に確実に設定しておくのがおすすめです。
まとめ
AWS Glue の開発において、ローカル実行環境を整えることは単なる効率化ではありません。
それは、試行錯誤の量を増やし、実装の質を上げるための土台作りです。
- Glue 公式 Docker イメージで Spark / Glue 実行環境を揃える
- LocalStack で S3 をローカル再現する
- pytest で入出力を含めた ETL処理の テストを回せるようにする
今回の解決策に辿り着く前の私にとって、Glue ジョブの開始ボタンをポチッと押してからの「数分間の空白」が一番の曲者でした。ログが出るのを待つ間にちょっとSlackを覗いたり、別のタブを開いたり。その数分の間に、せっかく組み立てた思考の糸口はどこかへ行ってしまいます。
この「数分の待ち」を「数十秒の確認」へ。たったこれだけの短縮で、開発体験はガラッと変わります。
実装、テスト、修正を即座に繰り返す。この高速なフィードバックループこそが、エンジニアにとって一番心地よいリズムです。CloudWatchの画面を何度もリロードしながら「あれ、何を確認するんだっけ?」となる日々とは、もうおさらばしましょう。
投稿者プロフィール

-
BS事業部の秋田です。
PythonやAWS、Linuxを中心にシステム開発やインフラ設計に携わっています。
日々の業務や学びの中で得た知見をQiitaなどで発信しており、現場で役立つ技術やノウハウをわかりやすく共有することを心がけています。
最新の投稿
 AWS2026.04.13【AWS】LocalStack と公式コンテナで構築する AWS Glue のローカル開発環境
AWS2026.04.13【AWS】LocalStack と公式コンテナで構築する AWS Glue のローカル開発環境 AWS2025.11.21【AWS】Androidサブスク実装のバックエンド処理を解説!
AWS2025.11.21【AWS】Androidサブスク実装のバックエンド処理を解説!