はじめに
前編ではSpringBootの定期実行機能を使用して、Rcloneを実行する方法について解説しました。
【AWS】Rclone × S3 Selectによるデータ取り込み自動化で効率的なデータ活用を実現!~Rclone編~
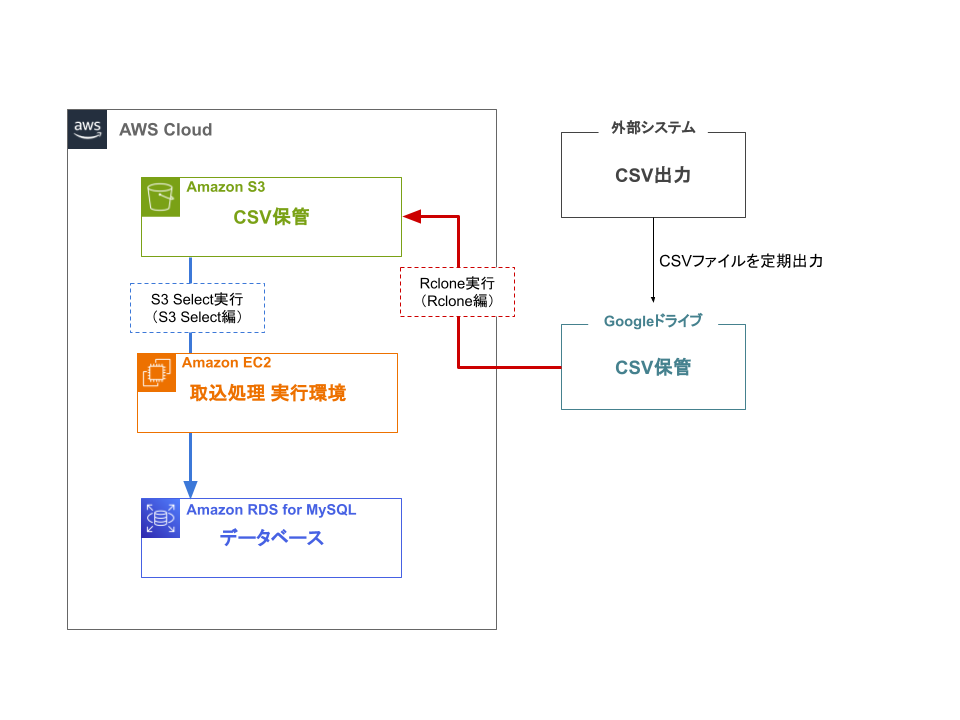
後編では、Amazon Simple Storage Service(Amazon S3、以下「S3」と記載)に保管されているCSVファイル内のデータをAmazon RDS for MySQLに反映させる方法について解説します。今回は前編で記載した通り、電子帳簿保存システムと販売管理システムのデータを定期的にデータベースに取り込むことが目的であり、CSVファイルに保管された大量のデータから必要な部分のみを抽出しデータベースに反映させることで、情報の一元化やデータ活用が可能になります。
S3 Select
AWSのストレージサービスであるS3に保管されたCSV、JSON形式のオブジェクトからSQLのSELECT文を用いてデータを取得するサービスです。他にもオブジェクト内のデータ全てを取得するメソッドなども存在しますが、データをフィルタすることで必要なデータのみ取得できる点がS3 selectの魅力の一つです。
S3 Selectを使用する理由
S3 Selectは他の取り込み方法と比較して低料金かつ、一般的なSQL関数が使用できることが今回選択した理由です。
またS3 SelectはS3のコンソール画面やCLI、SDKなどで実行することができますが、前編で紹介したRcloneとセットでSpringBootによる定期実行を実現したいため、今回はAWS SDK for Java 2.23.3を使用して実行します。
参考:Amazon S3 Select を使用したデータのフィルタリングと取得
今回は取得したCSVファイル内のデータをJavaのライブラリであるOpenCSVで整形し、同じくJavaのライブラリであるMyBatisを使用してAmazon RDS for MySQLにデータを取り込みます。
環境情報
Java 17.0.9
SpringBoot 3.2.2
AWS SDK for Java 2.23.3
openCSV 5.7.1
MyBatis 3.0.3
AWS EC2
AWS S3
導入方法
使用しているツールはpom.xmlへの追記+import文への記述により使用しています。
・AWS SDK for Java 2.23.3
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<version>2.23.3</version>
</dependency>・openCSV 5.7.1
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.7.1</version>
</dependency>・MyBatis 3.0.3
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>使用するCSVファイル内のデータ
| ID | 列1 | 列2 | 列3 | 列4 | 更新日時 |
| 1 | 1-1 | 1-2 | 1-3 | 1-4 | 2024-02-16 13:16:02 |
| 2 | 2-1 | 2-2 | 2-3 | 2-4 | 2024-01-20 16:11:32 |
| 3 | 3-1 | 3-2 | 3-3 | 3-4 | 2023-09-10 13:41:30 |
| 4 | 4-1 | 4-2 | 4-3 | 4-4 | 2024-02-12 16:54:45 |
処理内容
▼サンプルコード(クリックで表示する)
import software.amazon.awssdk.services.s3.S3AsyncClient;
import software.amazon.awssdk.services.s3.model.CSVInput;
import software.amazon.awssdk.services.s3.model.CSVOutput;
import software.amazon.awssdk.services.s3.model.ExpressionType;
import software.amazon.awssdk.services.s3.model.InputSerialization;
import software.amazon.awssdk.services.s3.model.OutputSerialization;
import software.amazon.awssdk.services.s3.model.SelectObjectContentRequest;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.stereotype.Service;
@Service
@EnableConfigurationProperties
public class S3Service {
public void insertS3Data() {
String keyName = "csvファイルのパス";
String bucketName = "S3バケット名";
String query = "select * from s3object s";
S3AsyncClient s3Client = S3AsyncClient.builder().build();
InputSerialization inputSerialization = InputSerialization
.builder()
.csv(CSVInput.builder().fileHeaderInfo("IGNORE")
.allowQuotedRecordDelimiter(true)
.build())
.build();
OutputSerialization outputSerialization = OutputSerialization
.builder()
.csv(CSVOutput.builder().build())
.build();
SelectObjectContentRequest request = SelectObjectContentRequest
.builder()
.bucket(bucketName)
.key(keyName)
.expression(query)
.expressionType(ExpressionType.SQL)
.inputSerialization(inputSerialization)
.outputSerialization(outputSerialization)
.build();
}
}まず、S3 Select実行に使用するクライアントを設定します。S3 Select実行用のメソッドはS3AsyncClientに実装されているためそちらを使用します。
ほかにもS3 Selectを実行するために必要なSelectObjectContentRequestを作成します。
SelectObjectContentRequest作成に必要な設定は以下の通りです。
| key | 対象のS3バケットの名称を指定します |
| bucket | 対象のS3バケットからファイルにアクセスするためのパスを指定します |
| expression | データをフィルタするためのSQL文を指定します |
| inputSerialization | S3 selectの入力形式を設定します。入力形式とはS3 selectを実行する対象のファイル形式のことを指すため、今回はCSV形式に設定しています。 CSVファイルのフィールド内でレコード区切りに使用している改行コードなどが含まれる場合はallowRecordDelimiterをtrueに設定する必要があります。また、S3 SelectはSQL文の条件指定の際に日本語を使用したカラム名の指定ができないため、CSVファイルのヘッダーに日本語が含まれる場合はfieldHeaderInfoをIGNOREに設定し、「_1」のようなインデックス番号による条件指定を行う必要があります。 |
| outputSerialization | S3 selectの出力形式を設定します。S3 Selectで取得してきたデータの出力形式を指定することができ、ここでもCSV形式を設定します |
続いてSelectObjectContentRequestとともにS3 Select実行に必要なSelectObjectContentResponseHandlerを定義し、SelectObjectContentResponseHandler内でAmazon RDS for MySQLへのデータ取り込み処理も記述していきます。
▼サンプルコード(クリックで表示する)
import com.opencsv.CSVReader;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.core.async.SdkPublisher;
import software.amazon.awssdk.services.s3.S3AsyncClient;
import software.amazon.awssdk.services.s3.model.CSVInput;
import software.amazon.awssdk.services.s3.model.CSVOutput;
import software.amazon.awssdk.services.s3.model.ExpressionType;
import software.amazon.awssdk.services.s3.model.InputSerialization;
import software.amazon.awssdk.services.s3.model.OutputSerialization;
import software.amazon.awssdk.services.s3.model.RecordsEvent;
import software.amazon.awssdk.services.s3.model.SelectObjectContentEventStream;
import software.amazon.awssdk.services.s3.model.SelectObjectContentEventStream.EventType;
import software.amazon.awssdk.services.s3.model.SelectObjectContentRequest;
import software.amazon.awssdk.services.s3.model.SelectObjectContentResponse;
import software.amazon.awssdk.services.s3.model.SelectObjectContentResponseHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.stereotype.Service;
@Service
@EnableConfigurationProperties
public class S3Service {
@Autowired
S3Mapper s3Mapper;
public void insertS3Data() {
try {
String keyName = "folder/sample.csv";
String bucketName = "bucketName";
String query = "select * from s3object s";
S3AsyncClient s3Client = S3AsyncClient.builder().build();
InputSerialization inputSerialization = InputSerialization
.builder()
.csv(CSVInput.builder().fileHeaderInfo("IGNORE")
.allowQuotedRecordDelimiter(true)
.build())
.build();
OutputSerialization outputSerialization = OutputSerialization
.builder()
.csv(CSVOutput.builder().build())
.build();
SelectObjectContentRequest request = SelectObjectContentRequest
.builder()
.bucket(bucketName)
.key(keyName)
.expression(query)
.expressionType(ExpressionType.SQL)
.inputSerialization(inputSerialization)
.outputSerialization(outputSerialization)
.build();
SelectObjectContentResponseHandler myHandler = new SelectObjectContentResponseHandler() {
private List<SelectObjectContentEventStream> receivedEvents = new ArrayList<>();
private SelectObjectContentResponse Response = SelectObjectContentResponse.builder().build();
@Override
public void responseReceived(SelectObjectContentResponse response) {
this.Response = response;
}
// 取得したデータを格納
@Override
public void onEventStream(SdkPublisher<SelectObjectContentEventStream> publisher) {
try {
publisher.subscribe(receivedEvents::add);
} catch (Exception e) {
System.out.println(e);
}
}
// エラー出力
@Override
public void exceptionOccurred(Throwable throwable) {
System.out.println("throwable" + throwable);
}
// データ取得完了後の処理
@Override
public void complete() {
StringBuilder sb = new StringBuilder();
// RECORDSのみを抽出
for (int size = 0; size < this.receivedEvents.size(); size++) {
if (this.receivedEvents.get(size).sdkEventType() != EventType.RECORDS) {
continue;
}
RecordsEvent record = (RecordsEvent) this.receivedEvents.get(size);
SdkBytes sdkBytes = record.payload();
byte[] recordBytes = sdkBytes.asByteArray();
try {
sb.append(new String(recordBytes, "UTF-8"));
} catch (UnsupportedEncodingException e) {
System.out.println(e);
}
}
String resultAll = sb.toString();
//openCSVを実行
CSVReader reader = new CSVReader(new StringReader(resultAll));
List<dataForCSV> CSVList = new ArrayList<>();
try {
List<String[]> CSVreadAll = reader.readAll();
for (int i = 0; i < CSVreadAll.size(); i++) {
String[] array = CSVreadAll.get(i);
SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd hh:mm:ss",
Locale.US);
// すべて文字列で取得しているため、データによって数値や日付に変換
Integer column1 = Integer.parseInt(array[0]);
String column2 = array[1];
String column3 = array[2];
Date column4 = sdf.parse(array[3]);
dataForCSV data = new dataForCSV(
column1,
column2,
column3,
column4
);
CSVList.add(data);
}
reader.close();
// MyBatisを実行し、RDSにINSERT
s3Mapper.insertCsv(CSVList);
} catch (Exception e) {
System.out.println(e);
}
}
};
s3Client.selectObjectContent(request, MyHandler);
} catch (Exception e) {
System.out.println(e);
}
}
}
SelectObjectContentResponseHandlerを定義する際に、特に設定が必要な箇所について説明します。
| onEventStream | ここではS3 Selectで取得したデータを用意したreceivedEventsに格納しています。 |
| exceptionOccurred | 取得に失敗したときにエラー文を取得できます。 例えばS3の指定されたバケットやファイルが見つからない場合はここでエラー文を出力することができます。 |
| complete | onEventStreamで全てのデータが正常に取得できたときに実行されます。 receivedEventsに格納したデータの中にはレコード情報以外にも統計などの情報が含まれているため、EventType.RECORDSで絞り込んでappendでStringBuilderに格納しています。 さらにOpenCSVとMyBatisを使用してDBへのINSERTを行っています。 |
最後はselectObjectContentを使用してS3selectを実行しています。
(今回の記事と直接関係のないimport文は一部省略しています)
SQL文による条件指定について
上述したようにS3 Selectを使用した条件指定には日本語を使用することができないため、CSVファイル内のデータのヘッダーに日本語が含まれる場合はインデックス番号を使用したカラム指定を行う必要があります。
例えば1列目、2列目、4列目、6列目を取得したい場合は以下のように記述します。
String query = "select s._1,s._2,s._4,s._6 from s3object s"さらにWHERE句を使用して特定のデータのみを取得することができます。例えばカラムに更新日時などの日付が含まれている場合、基準にしたい日付をCSVファイル内のデータと同じ日付の形式で定義しString型に変換してSQL文に定義すると、日付で絞り込んでデータを取得することができます。
例)S3 Selectを実行する1週間前から当日までに更新されたデータのみを取得する場合
Calendar calender = Calendar.getInstance();
calender.getTime();
calender.add(Calendar.WEEK_OF_YEAR, -1);
Date calenderDate = calender.getTime();
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
String Date = dateFormat.format(calenderDate);
String query = "select s._1,s._2,s._4,s._6 from s3object s where s._6 > '" + Date + "'";実行した日付が2024年2月16日だった場合、1週間以内に更新されたデータのみ取得され以下のようなデータが取得されます。
| ID | 列1 | 列3 | 更新日時 |
| 1 | 1-1 | 1-3 | 2024-02-16 13:16:02 |
| 4 | 4-1 | 4-3 | 2024-02-12 16:54:45 |
サポートされているSQLの条件指定方法については公式ドキュメント(Amazon S3 Select の SQL リファレンス)をご確認ください。
定期実行
前編で解説したSpringBootの定期実行ファイルに追記すると以下のようになります。S3Service.javaで作成したメソッドをこちらで使用します。
▼サンプルコード(クリックで表示する)
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.beans.factory.annotation.Autowired;
@RestController
@CrossOrigin
public class SampleController {
@Autowired
S3Service s3Service;
@Scheduled(cron = "0 30 12 * * *", zone = "Asia/Tokyo")
public void sample() {
try {
ProcessBuilder processBuilder = new ProcessBuilder("sh",
"シェルスクリプトのパス");
Process process = processBuilder.start();
int exitCode = process.waitFor();
System.out.println("Script execution finished with exit code: " + exitCode);
if (exitCode != 0) { // exitCodeが0以外(Rclone成功失敗)の場合RDS取り込みはやらない
System.out.println("Rclone実行に失敗しました。");
} else { // exitCodeが0(Rclone成功)の場合RDS取り込みを実行
//S3selectの処理を記載
s3Service.insertS3Data();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}まとめ
後編ではS3に保管したファイルのAmazon RDS for MySQLへのデータ取り込みについて解説しました。S3 Selectの実行では非同期処理が行われており、開発経験の浅い私にとっては内容理解と処理実現に時間を要しました。
本記事作成時点ではAWS SDK for Java 2.0以上でS3 Select実行についての情報が少ないため、参考になれば幸いです。
投稿者プロフィール

-
2023年より新卒入社。
Vue.js、Java(SpringBoot)、 AWSを使用した開発を経験後、
現在はSAPを用いた開発案件でアプリ開発やサービス調査に取り組んでいます。
業務を通じて得た技術に関する記事を共有していきたいと思います。