

こんにちは。株式会社KYOSO BS事業部BSグループの奥田です。
Amazon Web Serviceが提供している「Amazon AppFlow」(以下、AppFlowとして省略)は、ノンコーディングでSaaSアプリケーションとデータ連携ができるサービスです。
どの分野においても言えることですが、時間経過に比例し、データも増えていきます。
Salesforceはリソースが限られており、増やすためには莫大なコストがかかってきます。
しかし、この方法でSalesforceのデータをAWSに退避させると、Salesforce上のレポート、ダッシュボードで扱うデータのみに制限し、他のデータはAWS上で保管しておけます。
Salesforce開発を進める上で、ストレージ容量で悩む方も少なくないのではないでしょうか。
そこで今回は、AppFlowを実際に使用し、スムーズな使い方や注意点、他サイトには記載のない内容等について記載していきます。
Salesforce技術者の方にとって、ストレージ容量の問題解決に繋がれば幸いです。
フローの作成手順
前提として、Salesforce、AWSのアカウントがある想定で進めていきます。
今回は、SalesforceのオブジェクトにあるデータをAWSのS3に移行します。
AWSのサービス一覧からAppFlowを選択することで、以下のような画面になります。
ここで、「フローを作成」を選択することで、AppFlowの作成画面に遷移します。
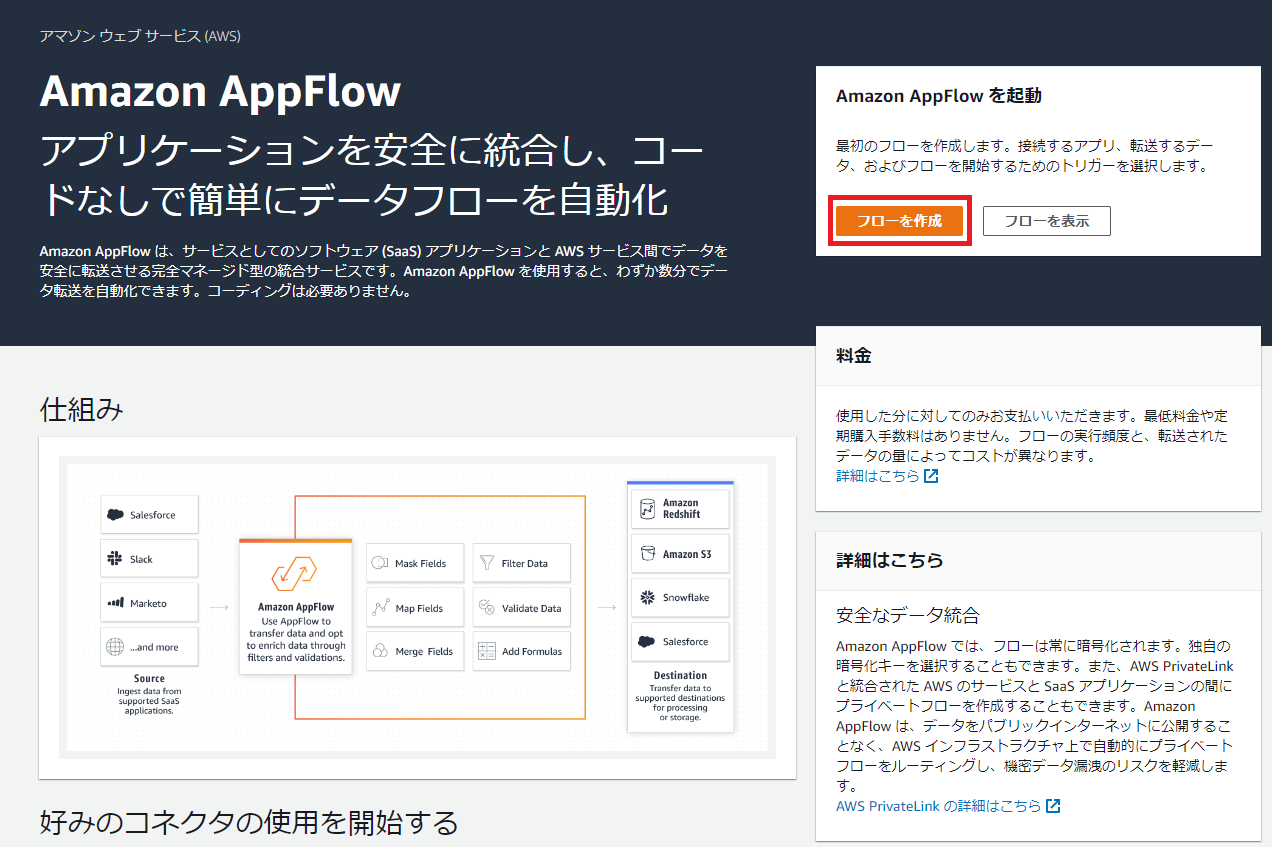
図1.AppFlow作成画面
最初にフロー名、フローの説明、データ暗号化、タグを指定します。
フロー名は、英数字と特殊文字 !@#.-_ の組み合わせで、以前のフロー名と一致しないようにします。
フローの説明は、英数字と特殊文字 !@#-_?, の組み合わせで、2048 文字未満にする必要があります。
データ暗号化は、デフォルトでAWS が所有し管理するキーで暗号化されますが、「暗号化設定をカスタマイズする(高度)」にチェックを入れることで、AWS KMSキーを選択して暗号化することもできます。
タグについては、必要に応じて任意の値を入れます。
フロー名とデータ暗号化は、一度保存されてしまうと再編集ができなくなるので、注意が必要です。
ここまで設定できたら、「次へ」を選択します。
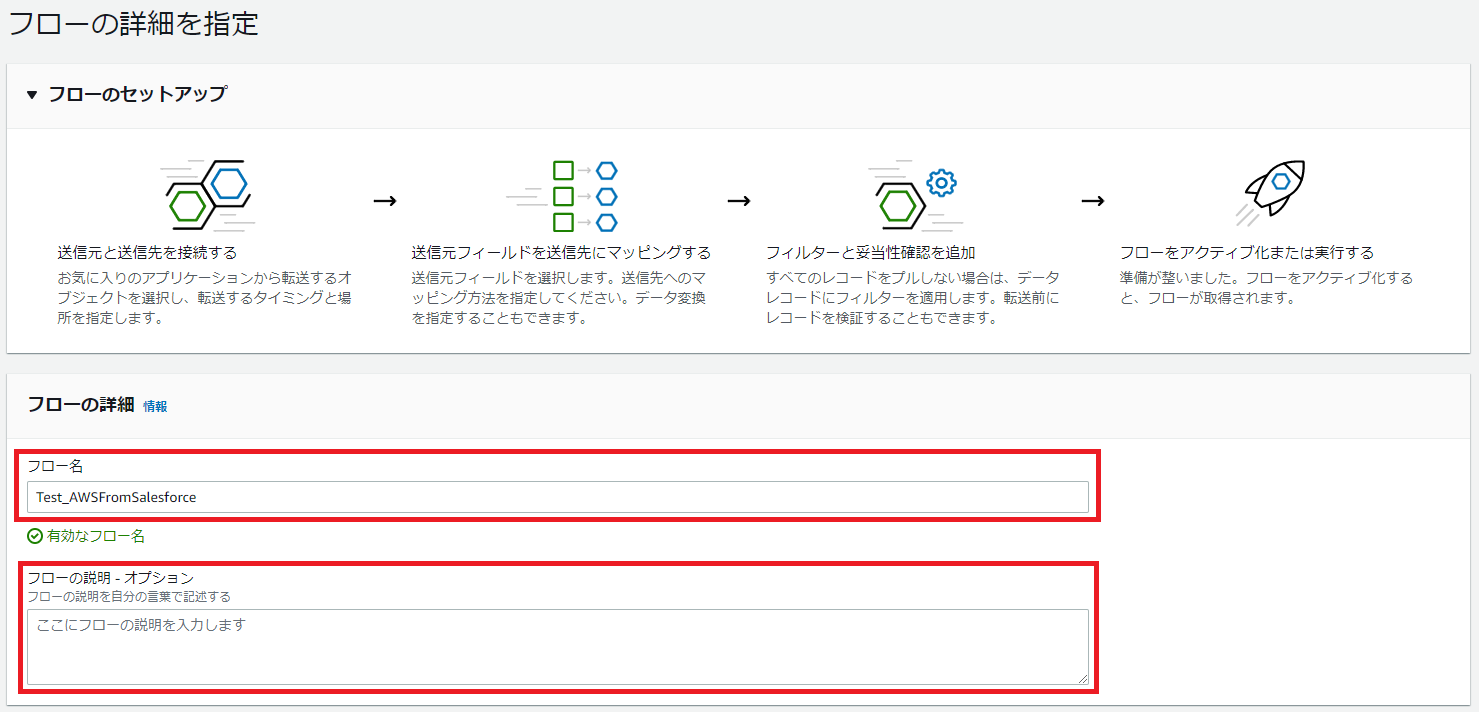
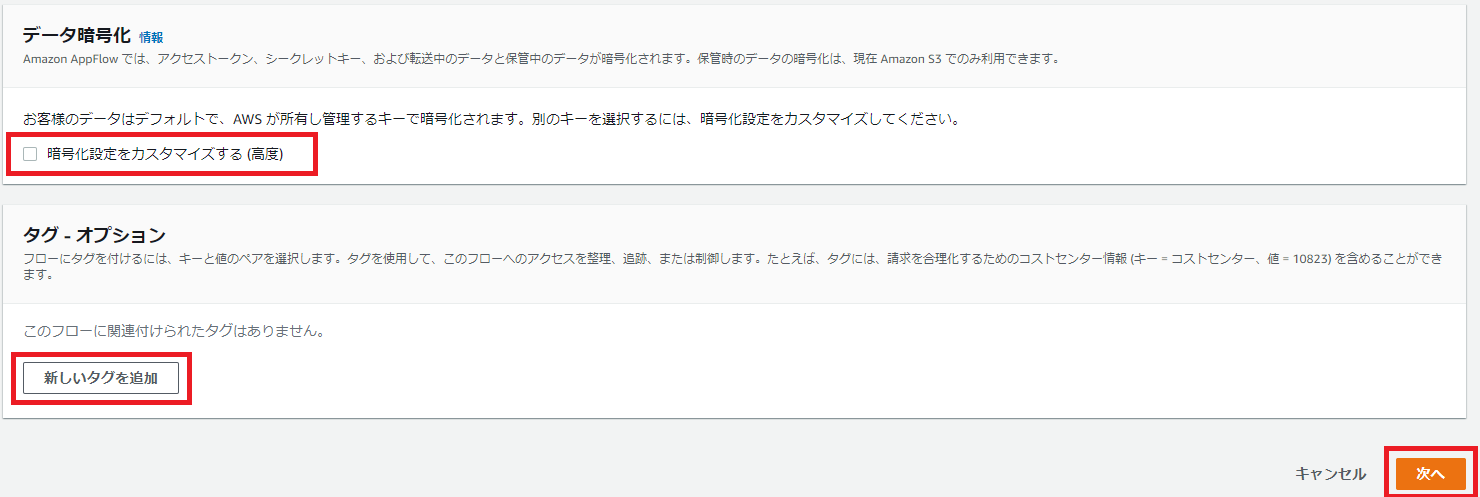
図2.フローの詳細設定画面
次に、接続先を指定します。
送信元名には、Salesforceを指定します。
「Salesforce接続先を選択」を選択して、「新規接続を作成」を選択します。
「AWS PrivateLinkで新規接続を作成する」を選択することで、Salesforceの非公開接続を使用することもできます。
一度、接続することで次回以降には「既存の接続」として再度接続情報を入力する手間が省けるようになります。
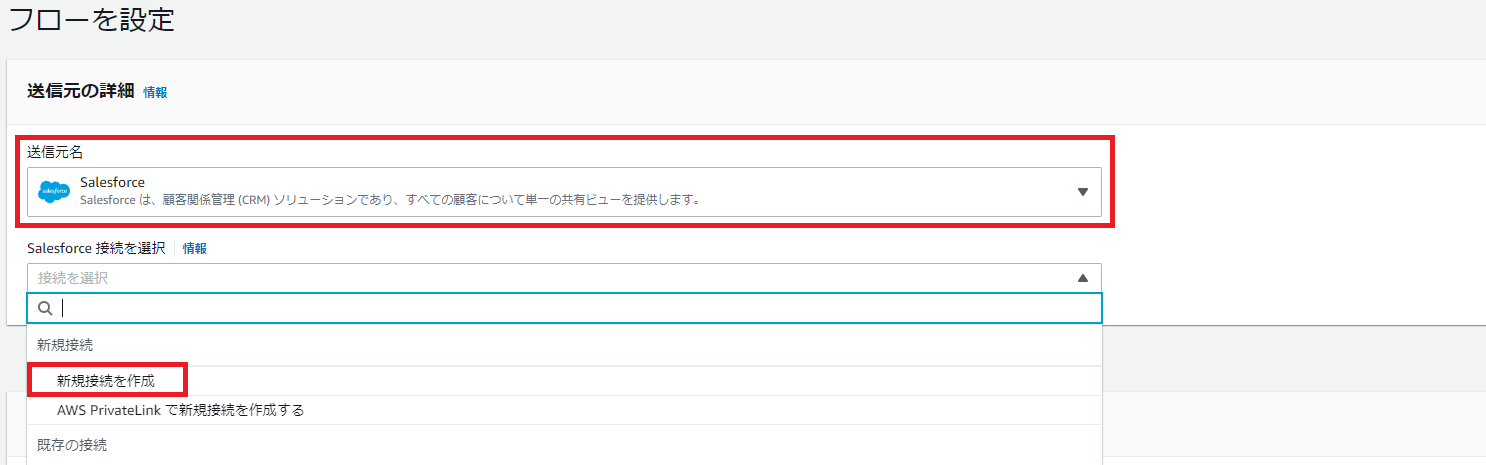
図3.フローの送信元設定画面
「新規接続を作成」を選択すると、Salesforce環境の詳細を入力する画面に遷移します。
接続名には、次回以降に「既存の接続」として表示されることも考慮し、英数字と特殊文字 !@#.-_+= の組み合わせで入力します。
接続名が入力できたら、「続行」を選択します。
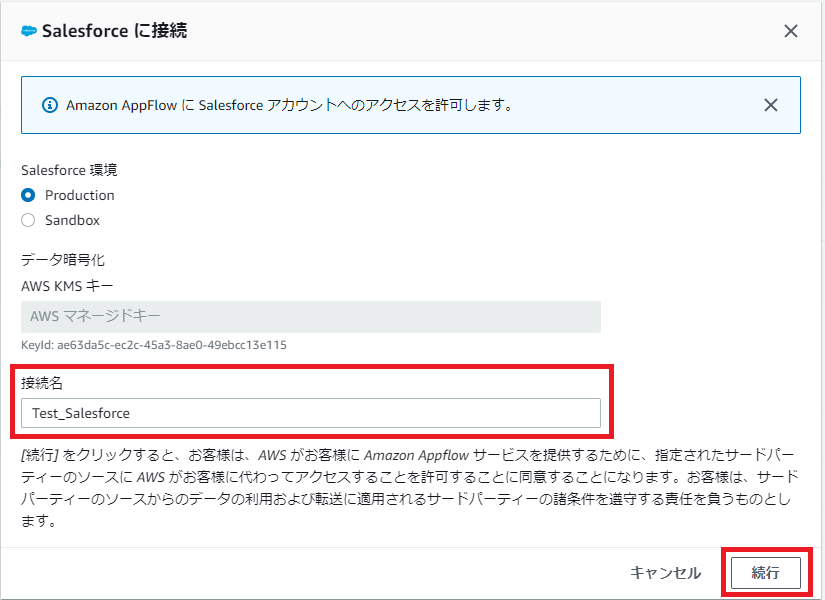
図4.Salesforce接続設定画面
Salesforceのログイン画面に遷移するので、接続するSalesforce環境にログインします。
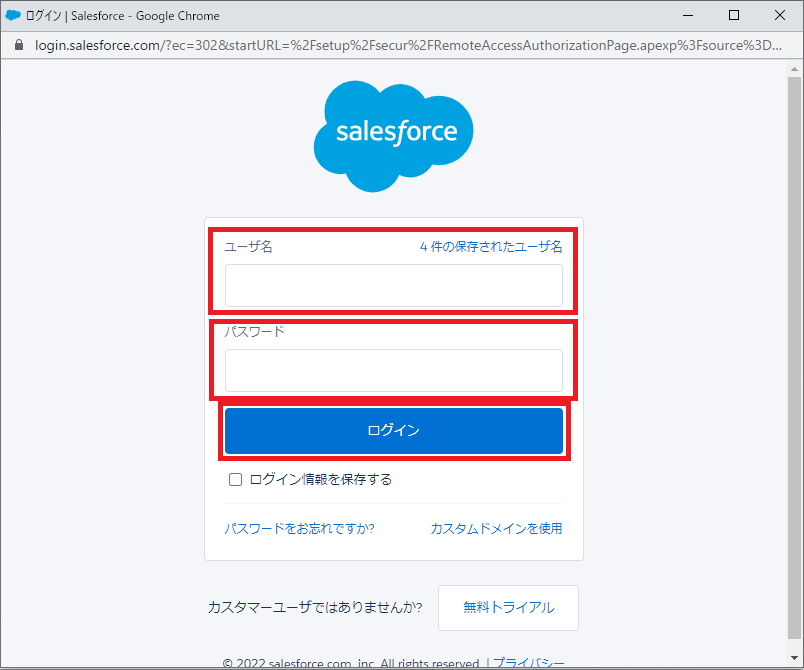
図5.Salesforceログイン画面
ログインが成功すると、「Salesforce接続を選択」に指定した接続名が表示されます。
次に、接続するオブジェクト(もしくはイベント)を選択します。
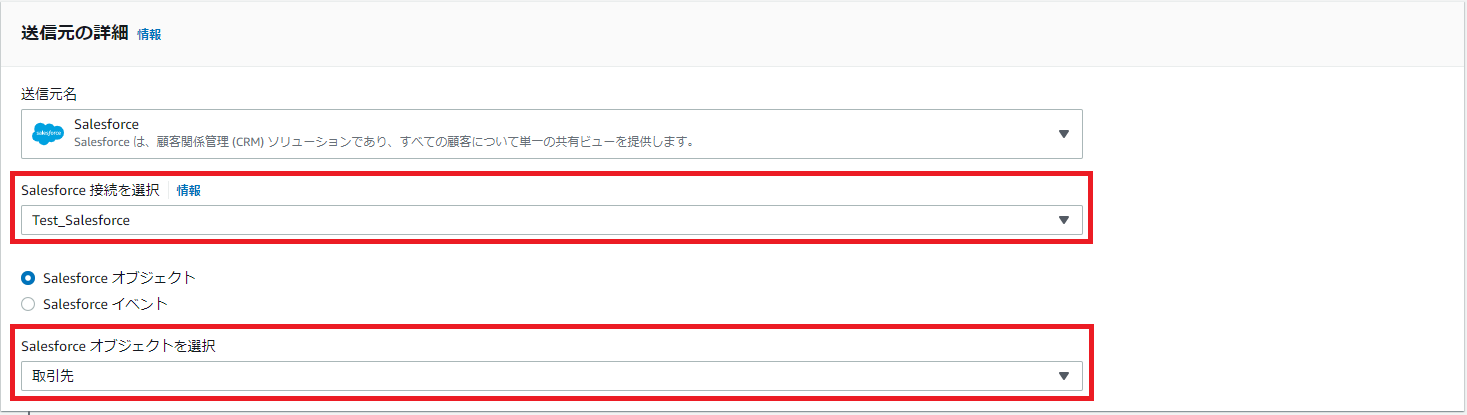
図6.フローの送信元設定画面(送信元設定後)
次に、送信先を指定します。
送信先名には、Amazon S3を指定します。
バケットの詳細には、データ格納先のバケットを指定します。
「バケットプレフィックスを入力」には、格納先がバケット直下ではない場合に、格納先のフォルダまでのパスを入力します。
送信先の詳細は、一度保存されてしまうと再編集ができなくなるので、注意が必要です。
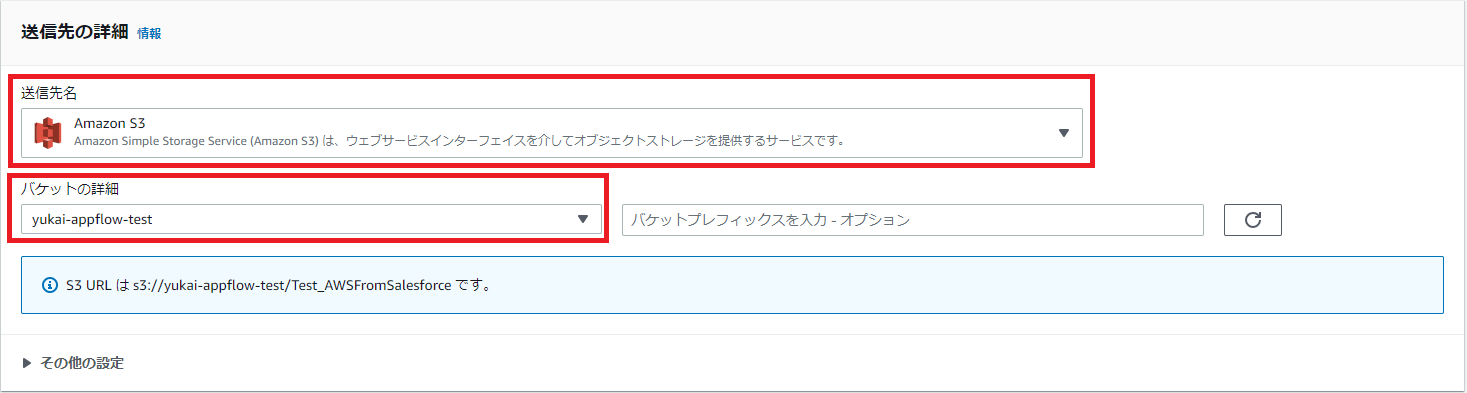
図7.フローの送信先設定画面
送信先の「その他の設定」では、以下のようにデータ形式やファイル名等、詳細な設定ができます。
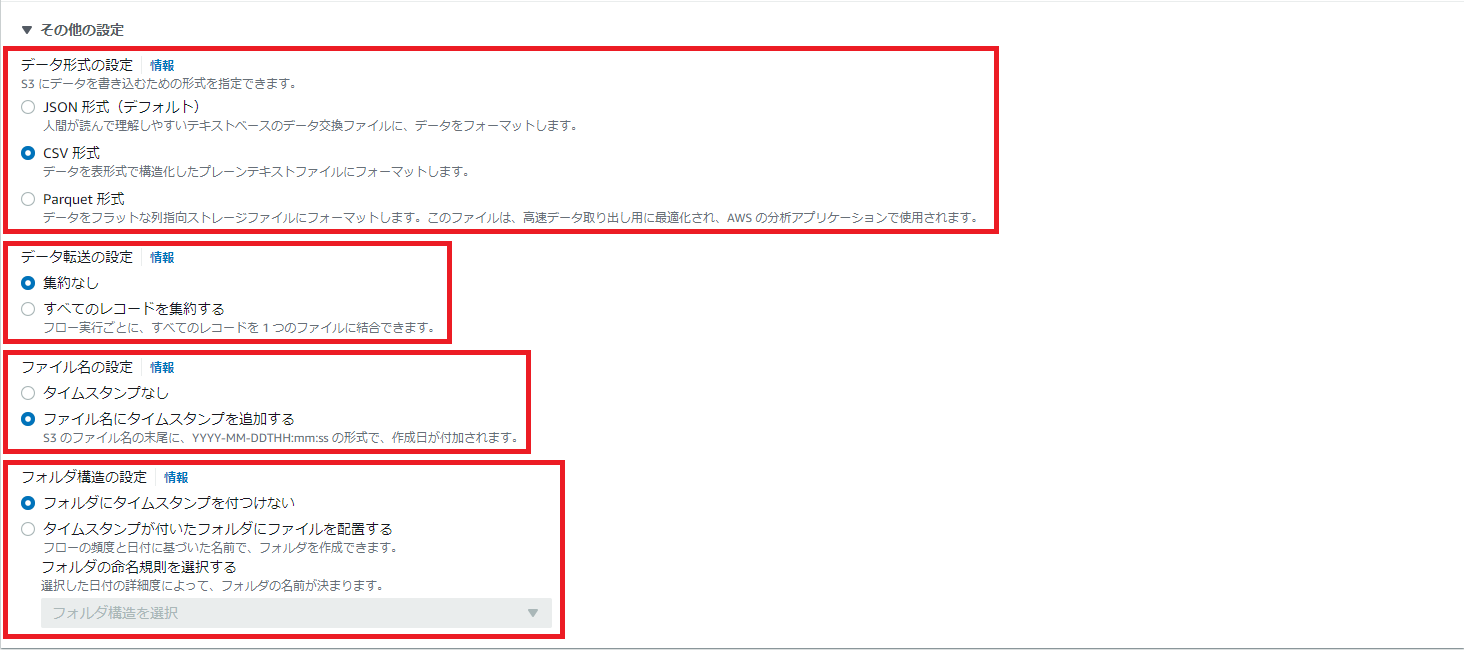
図8.フローのその他の設定画面
次に、フローを実行するタイミングを決めます。
「オンデマンド実行」を選択すると、フローを手動で実行できます。

図9.フロートリガー設定画面
「スケジュール通りにフローを実行」を選択すると、以下のようにスケジュールを設定してフローを自動で実行させられます。
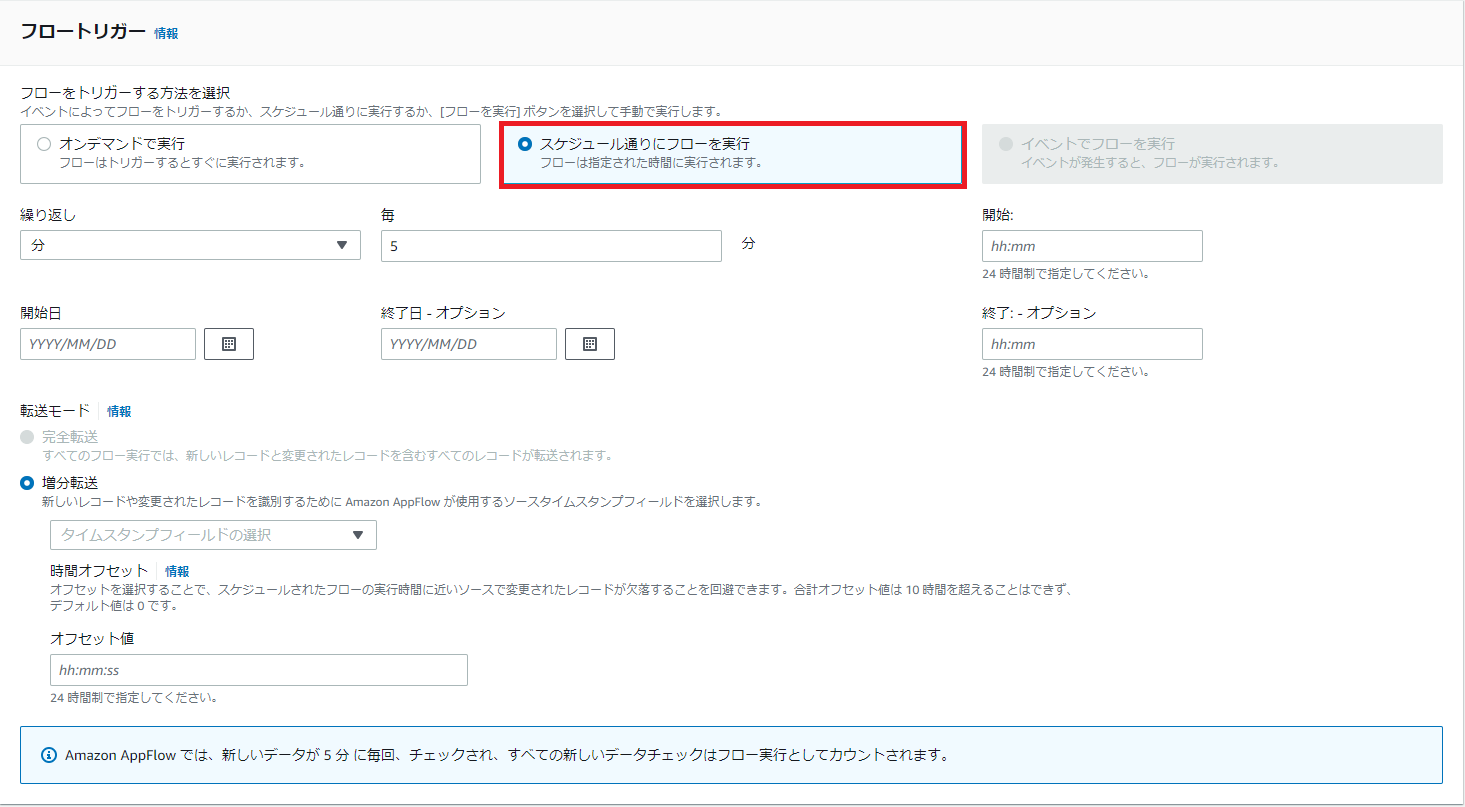
図10.フロートリガー設定画面(スケジュール実行押下時)
次に、データフィールドをマッピングします。
手動で必要な項目のみマッピングできます。
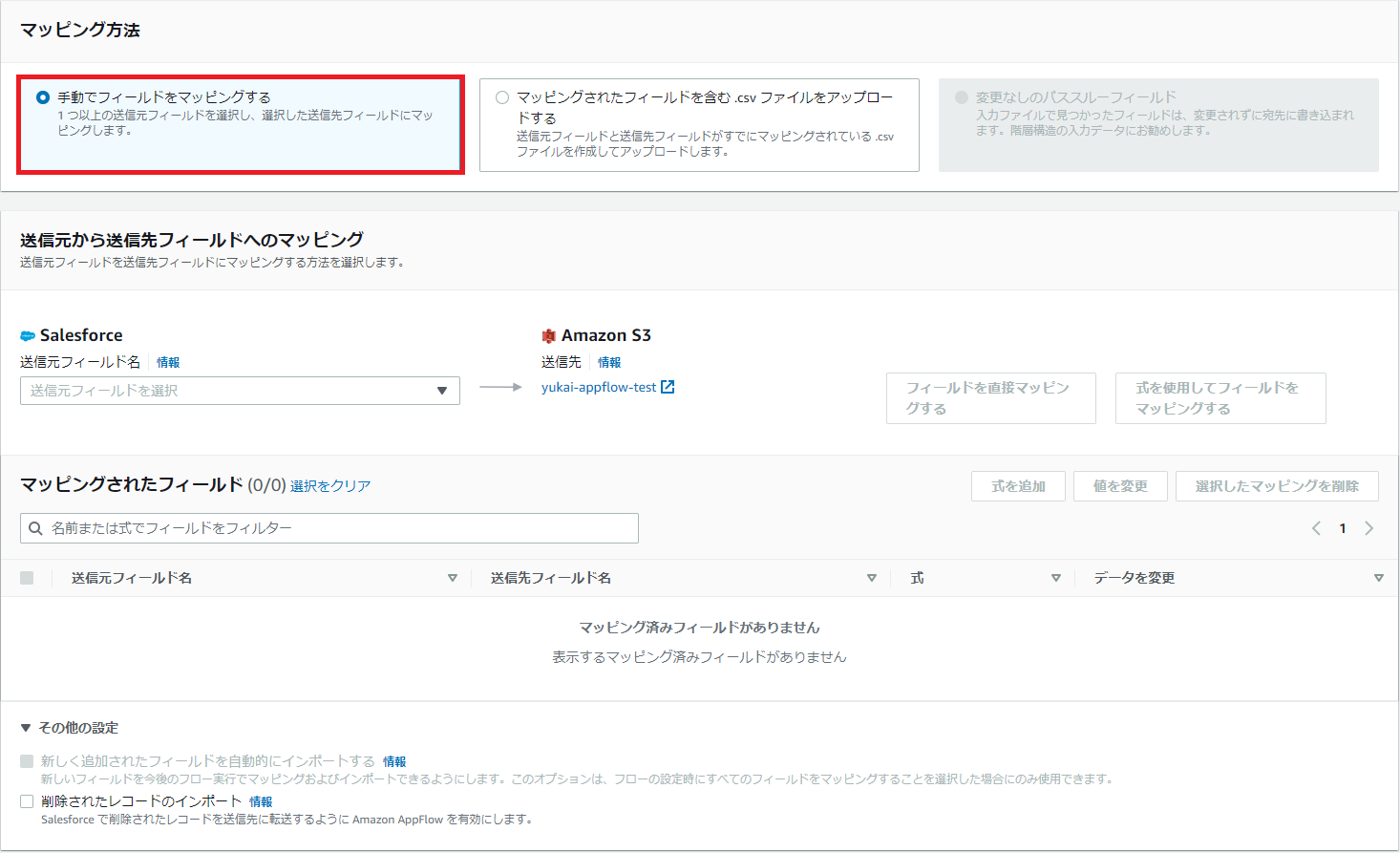
図11.マッピング設定画面(手動マッピング押下時)
また、マッピングされたCSVを使っても自動マッピングさせられます。
図12のようにカンマで区切られた 1 行で、それぞれのソースフィールドとターゲットフィールドのペアを指定し、 CSV ファイルを作成します。
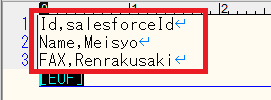
図12.マッピング用CSVファイル
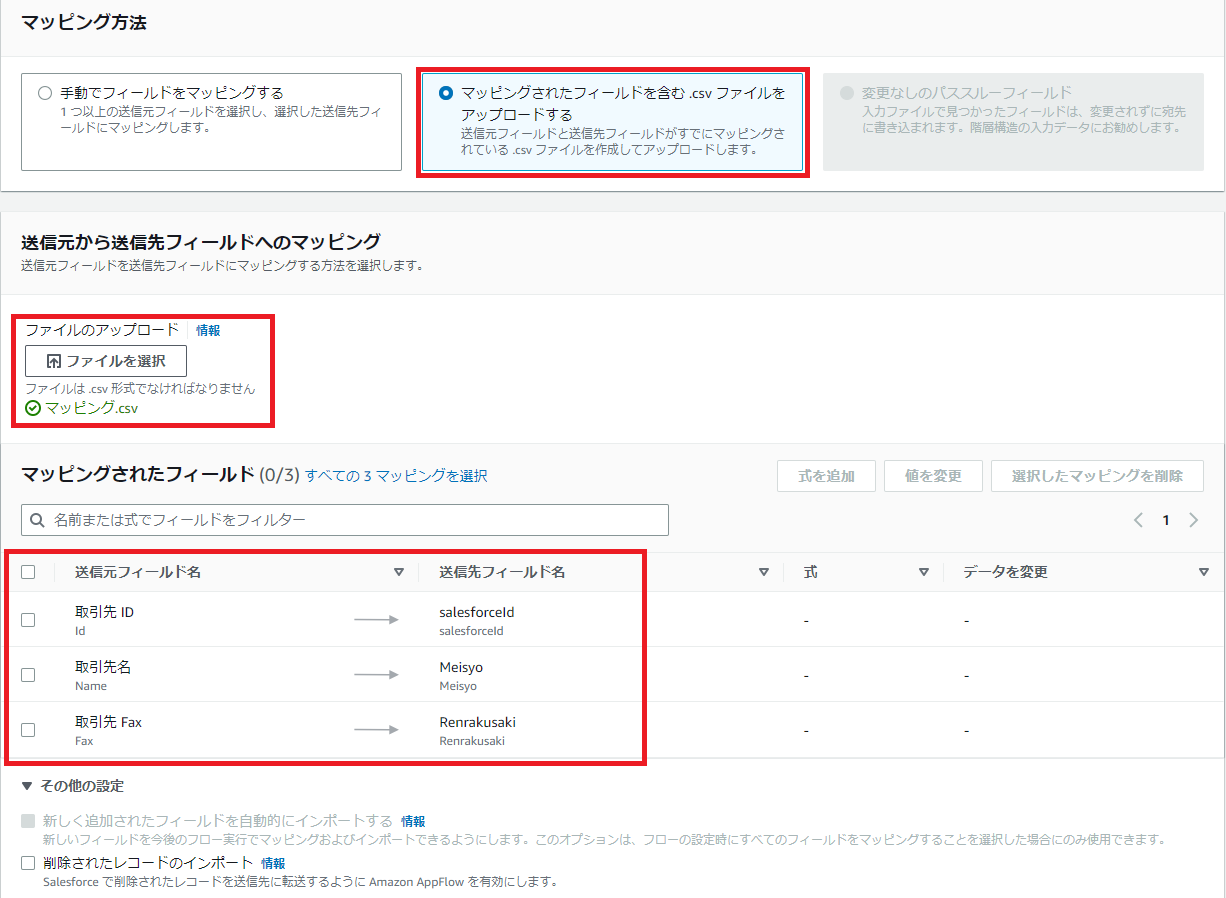
図13.マッピング設定画面(CSVマッピング押下時)
データの妥当性を確認し、無効なデータはフロー実行の対象外にできます。

図14.妥当性確認設定画面
次に、フィルターを追加します。
フィールド名、条件を指定すると扱いたいデータのみに絞り込めます。
但し、条件としてはリテラルの値のみ指定可能で、動的な値を扱うことはできません。
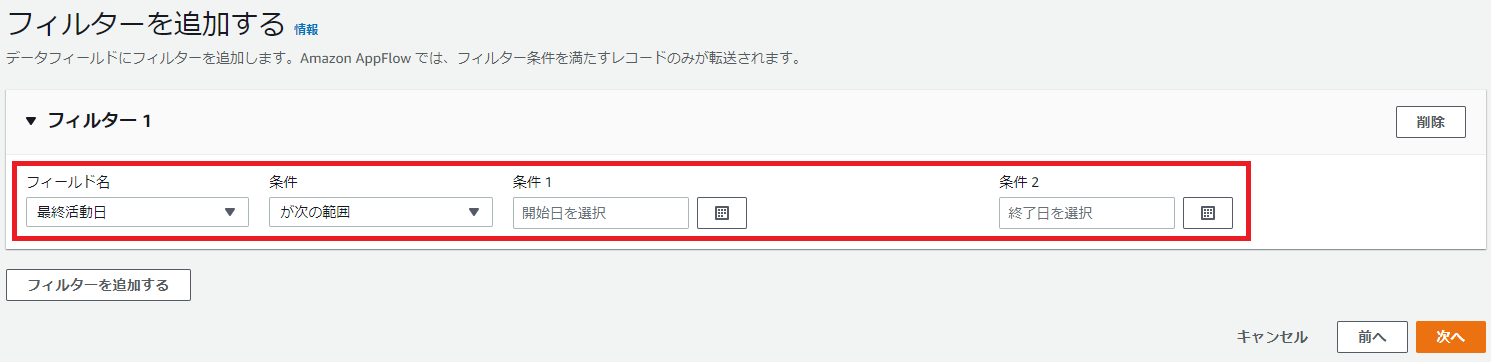
図15.フィルター設定画面
最後に、「フローを作成」を選択すると、フローの作成が完了します。

図16.フロー作成ボタン
「フローを実行」を選択すると、作成したフローを即時に実行することができます。
![]()
図17.フロー実行ボタン
フロー作成時の注意点まとめ
・フロー名とデータ暗号化、送信先の詳細は、一度保存されてしまうと再編集ができない。
・フィルター条件は、リテラルの値のみ指定可能で、動的な値を扱うことができない。
最後に
今回は、実際にAmazon AppFlow を使用してSalesforceとAmazon S3を連携してみました。
想定していたよりも簡単で、既にAWSを使用されている方であればすぐに実装できると感じました。(私は今回初めてAWSを触りましたが、問題なく動かすことができました。)
注意点にも記載しましたが、AppFlow は作成時点でしか決められない設定内容があり、それを知らない状態で安易に作成してしまうと、いくつもAppFlowを作成し直さないといけなくなります。
事前に知っておくことで、不要なフローを作成することなく、スムーズにSalesforceとAWSの連携をできます。AppFlowを作成する際の参考にしていただければ幸いです。
今回のように、Salesforceの課題となるストレージ容量をAWSで補完することで、より一層Salesforceでの実装の幅を増やせると考えております。
今後もSalesforceとAWSの連携を進めていき、不明点等やタメになった内容がありましたら投稿していきます。
参考
・Amazon AppFlow が新たに Salesforce 統合のサポートを開始
投稿者プロフィール

-
技術領域:VB、Salesforce
経験:建築業務向け生産支援システム、管理会計システム



