


前回執筆したブログでは、Kinesis Data AnalyticsからManaged Service for Apache Flink(以下、Flink)への移行について解説しました。移行が完了し、いざ運用フェーズに入ると、「どのメトリクスを注視すべきか」「予期せぬ再起動にどう立ち向かうか」といった課題に直面しました。
本記事では、Kinesis Data AnalyticsからFlinkへ移行した後の運用設計において、特に重要となる「監視メトリクスの解釈」と「パフォーマンス維持のための実装のポイント」について解説します。
▼この記事は以下の方を対象としています
- Flinkの運用を開始した、あるいは検討しているエンジニア
- 本番での安定稼働を意識したFlinkのアプリ開発をしたいエンジニア
- Flinkのメトリクス監視で、どのアラームを設定すべきか悩んでいる方
▼本記事で取り扱わないこと
- Flinkの基本的な環境構築手順(AWS CDKやCloudFormationの設定など)
- Kinesis Data Analyticsからの具体的なマイグレーション手順
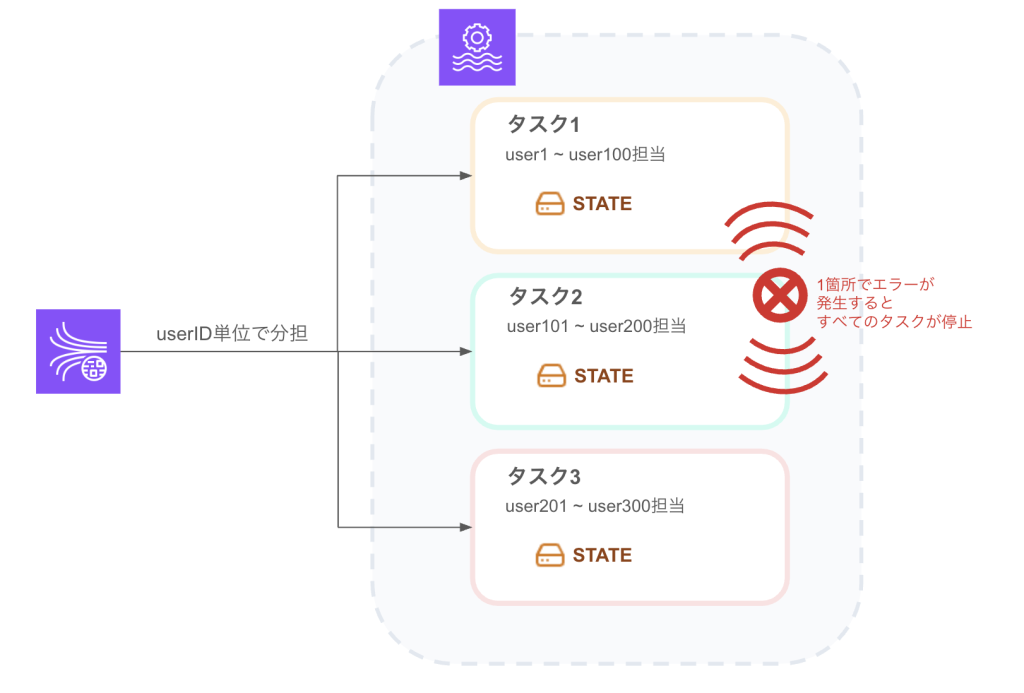
Flinkを支える「分散タスク」と「ステート」
Flinkの運用を理解する上で不可欠なのが、「計算リソースが分散され、それぞれのタスクが記憶(ステート)を持ちながら動いている」という構造をイメージすることです。
分散タスクとKPU(Kinesis Processing Unit)
Flinkでは、計算リソースの単位として KPU が使われます。アプリケーションがスケールする際、このKPUという箱が増え、その中で処理が分散タスクとして分割されて実行されます。
- 分散することのメリット: 膨大なストリームデータを複数のタスクで分担して処理できるため、極めて高いスループットを実現できます。
- 分散することの代償: 処理が細かく分かれている一方で、それらは一つのジョブとして密結合しています。どれか一つのタスクでエラーが発生すると、原則としてジョブ全体が再起動されます。
ステートとチェックポイント
分散された各タスクは、ステートを保持しています。ステートとは、ストリーム処理の途中で保持される一時的なメモリ(記憶領域)のようなものです。ステートを保持することで、以下のような高度な処理が可能になります。
- 集計処理: 「過去5分間の売上合計を出したい」といった、時間の幅を持った計算
- 重複排除: 「同じIDのデータが来たら2回目は無視したい」という判定
- ストリーム結合: 「Aのデータが来た後、1分以内にBのデータが来たら結合する」という複雑な条件付け
つまり、ステートはFlinkが「過去に何が起きたか」を覚えておくための装置です。
そしてステートを使ったバックアップの役割を果たすのがチェックポイントという仕組みです。Flinkは各タスクが持っているステートのスナップショットをチェックポイントとしてS3などの外部ストレージに定期的に保存しています。もしタスクのエラーで全体が再起動しても、このチェックポイントから記憶を復元することで、失敗した直前の状態から処理を再開できるようになっています。
安定稼働のために注視すべき5つの主要メトリクス
運用フェーズにおいて、システムの異常を早期に検知するために私たちが監視対象としている主要なメトリクスを紹介します。
| メトリクス名 | 監視する理由・目的 |
|---|---|
| CPU Utilization | 上昇傾向にある場合、スループットが追いつかずレイテンシーに悪影響が出るため、リソース不足の予兆として監視します。 |
| fullRestarts | 値が0でない場合、アプリ内部で何らかのエラーが発生している可能性が極めて高いため、異常検知の第一指標とします。 |
| uptime | 意図しないリセット(数値の急落)はアプリのエラーを示唆します。また、マネージドサービス側でのセキュリティパッチ適用に伴う再起動の確認にも利用します。 |
| lastCheckpointDuration | ステートの肥大化や書き込み負荷を検知することができます。ここが延び続けると、最終的にアプリ全体の停止や遅延に繋がります。 |
| busyTimeMsPerSecond | アプリの過負荷を検知することができます。逆に値が常に低い場合は、上流からデータが流れてきていない可能性を疑います。 |
メトリクスの罠:fullRestarts は「最大値」を見る
前述の主要メトリクスの中でも、特に fullRestarts(Flink 2.2以降では numRestarts)には大きな落とし穴があります。
「累計値」を集計する際の計算ミス
fullRestarts は、アプリケーションを起動してからジョブが再開された回数の累積値を表すメトリクスです。
例えば、1分間の集計期間(00:00:00 〜 00:01:00)の間に、2回の再開が発生したとします。CloudWatchのデータポイントが15秒おきに記録されている場合、統計情報の取り方で結果が大きく変わります。
- 00:00:15 — 1 (1回目の再起動)
- 00:00:30 — 1
- 00:00:45 — 2 (2回目の再起動)
ここで統計情報を「合計(Sum)」にしてしまうと、期間内のデータポイントが単純加算され、0 + 1 + 1 + 2 = 4 という値が算出されます。 実際には2回しか再起動していないのに、メトリクス上は4回として表示されてしまうのです。
解決策:統計値には「最大(Maximum)」を使用する
この重複加算を防ぐためには、統計情報を最大(Maximum)に設定する必要があります。最大値であれば、期間内の最大値である「2」が正しく返されます。アラームの閾値設定や、エラーの調査をする際は、必ず最大を選択しましょう。

現場で遭遇した遅延と再起動:KDSの読み取り制限
運用開始後、あるタイミングでアプリの再起動が発生しました。調査の結果、データソースであるKinesis Data Streams (KDS)の読み取りにおいて getRecords が失敗していることが判明しました。
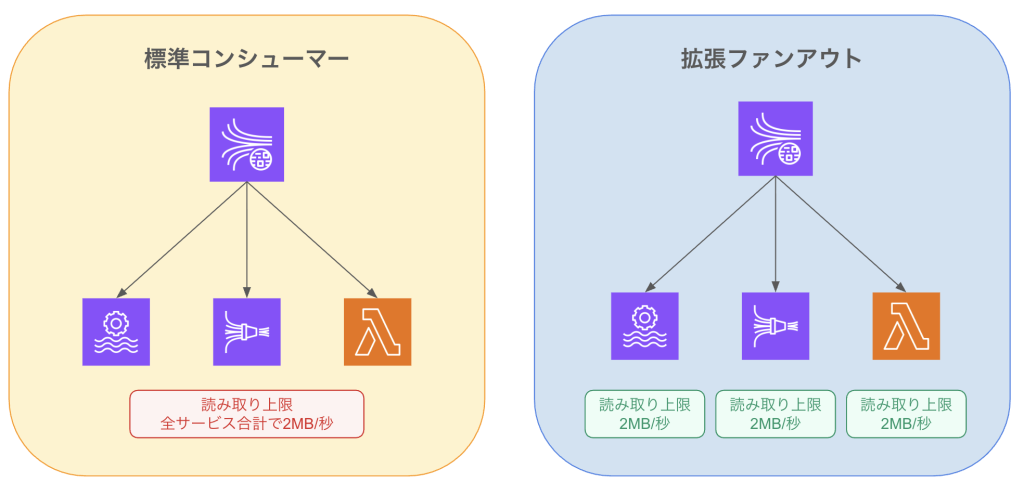
コンシューマー競合によるボトルネック
KDSの標準的なコンシューマーは、1シャードあたり合計で 2MB/秒 のスループットを共有します。 今回の構成では、同じKDSをFlinkだけでなくFirehoseも同時に参照しており、データ送信頻度が高まった際にこの制限を奪い合う形になっていました。その結果、Flinkがデータ取得に失敗し、再試行するタイミングでgetRecordsするための認証のトークンが失効され、再起動を招いたのです。
解決策としての「拡張ファンアウト」
この事象を根本解決する手段は 「拡張ファンアウト(Enhanced Fan-Out)」 の有効化です。これを利用することで、各コンシューマーに専用の読み取り枠(2MB/秒)が割り当てられ、他サービスの負荷に影響されずにデータを取得できるようになります。
アプリ実装で考慮すべき「運用のための2設定」
① 不正データに対する再試行回数の調整
不正データが流入した際、Flinkはデフォルトで 3回 再試行を行います。 3回リトライしてもエラーの場合、ジョブはそのデータをスキップして次を読み込みます。「データの欠損を許容せず止めて調べるか、リアルタイム性を優先して切り捨てるか」という要件に合わせて max_attempt (pythonで実装するPyFlinkの場合)を調整する必要があります。
② ステートの肥大化を防ぐ「TTL(Time To Live)」
運用が長くなると lastCheckpointDuration が上昇し続けることがあります。これは、古いステートデータが残り続けていることが原因の一つです。 これを防ぐには、ステートデータに対して TTL(有効期限) を設定することが不可欠です。ステートサイズを一定に保ち、バックアップの遅延を未然に防ぎましょう。
現場でのトラブル調査:ログの難しさと向き合う
本来はFlinkアプリはJavaで実装するのですが、スキルセットの関係でFlinkアプリはpythonで実装しています。これによりログ調査でも心が折れる場面がありました。
なぜPythonなのにJavaのログが出るのか?
実装したpythonコードは、内部的にはJavaのJVM上で呼び出して動作しています。そのため、エラーが起きるとCloudWatch LogsにはJavaの巨大なスタックトレースが出力されます。
- Javaの知見が求められる: エラーメッセージが見慣れず、どこまでがライブラリのログで、どこが自分のコードの問題かわからない事態に陥りがちです。
- 対応関係の不明瞭さ: Java側で RuntimeException が出ていても、それがPythonコードの何行目に起因しているかの特定が非常に困難です。
ログを調査する際は「Caused by:」等のキーワードでエラーの根本原因を探すことがポイントです。
まとめ
実際にFlinkの運用を始めて感じたことは、KinesisDataAnalyticsとは運用観点が異なることが多い、という点です。Flinkへの移行時はステートのTTLやログの見方など多くのことを理解しきれておらず、手探りの状態でした。実際に運用を開始して初めて、メトリクスの集計方法の誤りやKDS競合によるトークンの失効、ステート肥大によるチェックポイント処理の負荷上昇、等多くの気づきを得ることができました。今回得た教訓を記事にすることで同じ失敗をする方が一人でも減り、Flink運用の参考になれば幸いです。
参考文献
AWS公式ドキュメント:Managed Service for Apache Flink でのモニタリング
AWS公式ドキュメント:Unbounded state growth
投稿者プロフィール

-
2017年新卒入社。
入社当時からAWSを用いた開発をしています。
その中でも、サーバーレス構成をメインにしたアーキテクチャ設計から構築・運用に従事しています。
新たに得た経験や技術を積極的に共有することを心がけています。

