はじめに
AWS Lambda 上で動く Python 処理は、機能要件さえ満たせば一旦動いてしまうため、性能面の改善は後回しになりがちです。「DynamoDB アクセスの積み上げ」「S3 のファイルの大量取得」などといった処理は、いずれも単体では数十ミリ秒オーダーで済むため、単体テストの段階ではまず問題として表面化しません。ところが、結合テストでデータ量や呼び出し回数が現実的になり、パフォーマンステストや本番運用で同時実行数が増えてくると、これらが一気に積み上がり、無視できないレイテンシやコストとして顕在化します。こうした箇所は後工程で気づくほど手戻りや調査コストが大きくなるため、設計・実装の段階できちんと押さえておくのが望ましい領域です。
本記事では、実案件で取り組んだ Python × Lambda の高速化・効率化のうち、効果を確認できた以下5つの改善を紹介します。
– DynamoDB の Query 並列化と Lambda メモリ設定の組み合わせ
– RDS トランザクションスコープの最小化
– Lambda Layer のトップレベル初期化を軽くする
– S3 取得時の HeadObject を省く
– Lambda トップレベルでの lru_cache メモ化
▼ 対象読者
– Lambda 上の Python 処理の性能を継続的に改善したい方
– DynamoDB や S3 を多数呼ぶワークロードで、レイテンシに頭打ち感がある方
– 「Lambda Layer に何を入れるべきか」をチームで議論している方
– 設定値・マスタデータを毎回外部から取得している実装を見直したい方
本記事で取り扱わないこと
以下の内容は本記事の範囲外です:
– VPC、IAM、CDK の基礎構築手順
– DynamoDB / RDS の詳細なスキーマ設計やキー設計の話
– Provisioned Concurrency や SnapStart など、Lambda の Init Duration そのものを縮める機能
– ベンチマーク結果の統計的な厳密性(各比較とも run_count = 7 の実測値です)
注記
本記事のコードおよびベンチマーク値は執筆時点(2026年5月、Lambda ランタイム python3.12、AWS CDK 2.140.0 以上、リージョン ap-northeast-1)の環境に基づきます。boto3 / botocore は Lambda ランタイム同梱版を使用。AWS の各サービス仕様、料金、Lambda ランタイム、SDK 実装は今後変更される可能性があるため、最新の情報は公式ドキュメントを参照のうえ、ご自身のワークロードで再計測を実施ください。
高速化内容
1. DynamoDB:最新N件 Query の並列化はメモリ設定とセットで初めて効く
課題点
IoTデバイスを画面で可視化する要件で、複数デバイスの時系列データから「デバイスごとの最新N件」を取得する処理がありました。DynamoDB のキーはデバイスIDをパーティションキー、イベント時刻相当の値をソートキーにしており、各デバイスに対して Query を ScanIndexForward=False、Limit=N で実行する形です。
この要件では、取得したいアイテムのキーを事前にすべて列挙できないため、内部で並列取得を行ってくれる標準の BatchGetItem では置き換えにくい状況でした。そのため、旧実装ではデバイスごとに Query を逐次実行しており、対象デバイス数が増えるほど API 往復が積み上がっていました。素直に ThreadPoolExecutor で並列化すれば速くなるはず、と考えて差し替えたところ、Lambda のメモリ設定が低い環境では「むしろ遅くなる」というケースが出てきました。
旧実装:デバイスごとに逐次 Query
def query_latest(device_id):
return table.query(
KeyConditionExpression=Key("pk").eq(device_id),
ScanIndexForward=False,
Limit=LATEST_N,
ConsistentRead=False,
)["Items"]
def sequential_query(device_ids):
items = []
# 単純な逐次取得
for device_id in device_ids:
items.extend(query_latest(device_id))
return items
新実装:デバイスごとに並列 Query + 接続プール拡張
ThreadPoolExecutor で並列化するとともに、botocore の HTTP 接続プールも広げます。スレッド数だけ増やして接続プールを広げないと、スレッドが HTTP 接続待ちで詰まり、並列化の効果が活きません。
import concurrent.futures
import boto3
from boto3.dynamodb.conditions import Key
from botocore.config import Config
PARALLEL_WORKERS = 16
dynamodb = boto3.resource(
"dynamodb",
config=Config(
max_pool_connections=PARALLEL_WORKERS,
retries={"mode": "standard", "max_attempts": 3},
),
)
table = dynamodb.Table(TABLE_NAME)
def query_latest(device_id):
return table.query(
KeyConditionExpression=Key("pk").eq(device_id),
ScanIndexForward=False,
Limit=LATEST_N,
ConsistentRead=False,
)["Items"]
def parallel_query(device_ids):
# ここで並列取得
with concurrent.futures.ThreadPoolExecutor(max_workers=PARALLEL_WORKERS) as ex:
results = ex.map(query_latest, device_ids)
return [item for device_items in results for item in device_items]実測結果
64デバイスについて、各デバイスの最新5件を取得した際の、Lambda メモリ別の逐次/並列比較(各7回平均)です。各デバイスには20件の履歴を投入し、1件あたりのペイロードは2KBにしています。
| Memory (MB) | 逐次 avg ms | 並列 avg ms | Speedup | 並列 GB秒 | 128MB並列比のコスト比 |
|---|---|---|---|---|---|
| 128 | 2233.778 | 3065.598 | 0.729 | 0.383200 | 1.000 |
| 256 | 1174.833 | 1619.119 | 0.726 | 0.404780 | 1.056 |
| 512 | 580.449 | 827.591 | 0.701 | 0.413795 | 1.080 |
| 1024 | 334.060 | 371.936 | 0.898 | 0.371936 | 0.971 |
| 2048 | 318.222 | 198.327 | 1.605 | 0.396654 | 1.035 |
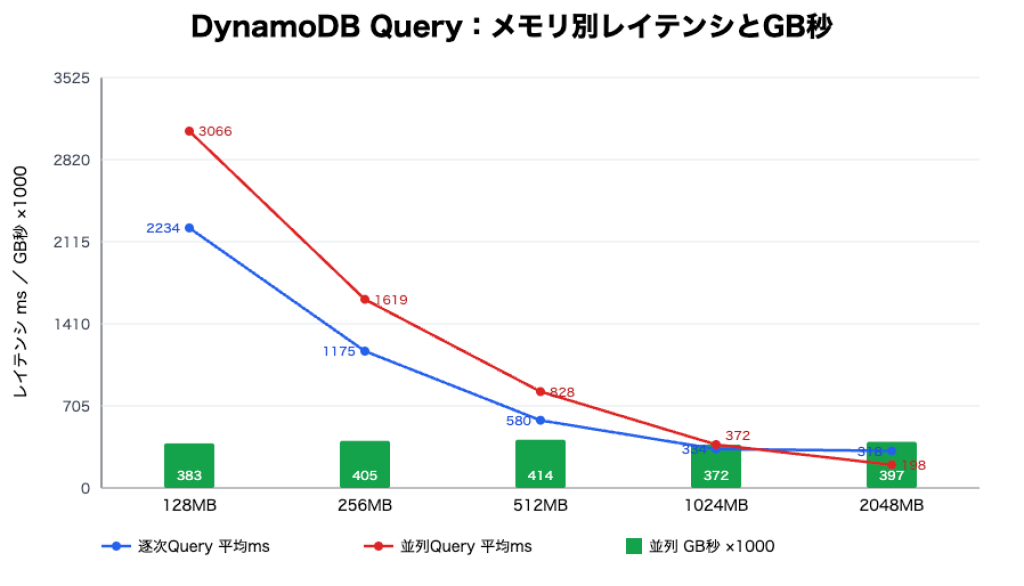
128〜512MB のレンジでは、逐次より並列の方が遅いという結果になりました。並列化処理を入れたことにより、低メモリの実行環境ではスレッド切り替え、HTTP 接続、レスポンス処理のオーバーヘッドが勝ってしまうためです。1024MB に上げてようやく逐次とほぼ並ぶようになり、2048MB で初めて並列が逐次を明確に上回り、約1.6倍の高速化を確認できました。
注目すべきはコスト側の数値です。128MB で並列実行した時の GB 秒を1.000とすると、2048MB で並列実行した時の GB 秒は1.035となります。レイテンシは 3065.598ms から 198.327ms まで短くなり、約15倍速くなっていますが、概算 GB 秒はほぼ同程度です。メモリ設定を上げた場合、実行時間に対するコストはその分上昇しますが、実行時間自体が減るためトータルのコストは変わらない、思っていたより増えないということがあります。
実装時の注意点
– ThreadPoolExecutor だけでなく、botocore.config.Config(max_pool_connections=…) を必ず合わせます。デフォルトは10で、ワーカー数より小さいと接続待ちで並列効果が薄れます。
– 「速くなる」「コストが下がる」は処理内容次第ですので、トータルでのGB秒を考慮して評価することをお勧めします。
2. RDS:トランザクションスコープに余計な処理を入れない
実測値はありませんが、Lambda × RDS で再現性が高く遭遇する設計上の問題なので合わせて紹介します。単発テストでは気づきにくく、Lambda が大量起動された瞬間にロック保持時間とコネクション占有が延びて、結果として「アプリは正しいのに本番で詰まる」という状態になりがちです。
旧実装:トランザクション内に外部 I/O が混ざる
def handler(event, context):
with session.begin(): # トランザクション開始
order = session.query(Order).filter_by(id=event["id"]).one()
order.status = "PAID"
session.add(order)
# DB整合性に直接関係しない処理がトランザクション内に混ざっている
invoice = s3.get_object(Bucket=BUCKET, Key=f"invoice/{order.id}.pdf")
billing_resp = http.post(BILLING_URL, json={"order_id": order.id})
payload = build_notification_payload(order, billing_resp.json())
sns.publish(TopicArn=TOPIC_ARN, Message=json.dumps(payload))このコードは1リクエストだけ動かしている分にはほとんど問題に見えません。S3 取得は数十ミリ秒、外部 API も数百ミリ秒程度で完了するためです。ところが同時に数百~数千の Lambda が起動して同じテーブルに触りに行くと、トランザクション開始から COMMIT までの間に S3 往復・外部 API レスポンス待ち・通知発行が積み上がります。RDS/Aurora のコネクションが解放されない時間が延び、行ロックの保持時間も延び、待ちが連鎖して秒単位のレイテンシ増加につながります。
新実装:トランザクション内は DB 整合性に必要な処理のみ
def handler(event, context):
with session.begin(): # トランザクション開始
order = session.query(Order).filter_by(id=event["id"]).one()
order.status = "PAID"
session.add(order)
# インデントを下げここでトランザクション終了。ロックとコネクションが解放される。
invoice = s3.get_object(Bucket=BUCKET, Key=f"invoice/{order.id}.pdf")
billing_resp = http.post(BILLING_URL, json={"order_id": order.id})
payload = build_notification_payload(order, billing_resp.json())
sns.publish(TopicArn=TOPIC_ARN, Message=json.dumps(payload))実装時の注意点
– 通知や S3 取得が失敗した場合の整合性は別途設計が必要になります。
– 「DB 更新に必要な参照」はトランザクション内に残す必要があります。外に出してよいのは、トランザクションと本質的には関係がないユーザー応答や副作用に限ります。
– RDS Proxy を使っている場合でも、トランザクション中はピン留めが発生してコネクション再利用が効きにくくなります。トランザクションを短く保つ意味はさらに大きくなります。
3. Lambda Layer:共通化のつもりで初期化コストを共有していないか
課題点
複数 Lambda で使うクライアント生成や辞書ロードを共通化しようとして Lambda Layer に詰め込み、しかも Layer モジュールのトップレベルで「重い初期化」を書いてしまうと、その Layer を使う全 Lambda が起動のたびに同じ初期化コストを払うことになります。利用 Lambda の数が増えるほど影響が広がる構造です。
旧実装:重いトップレベル
import boto3
# Layer import 時点で各クライアントを生成
S3 = boto3.client("s3")
DDB = boto3.client("dynamodb")
LAMBDA = boto3.client("lambda")
# Layer import 時点で大きな辞書を構築
PRECOMPUTED = {f"key-{i}": i * i for i in range(15_000)}新実装:軽いトップレベル + 遅延生成
import boto3
from functools import lru_cache
@lru_cache(maxsize=None)
def s3():
return boto3.client("s3")
@lru_cache(maxsize=None)
def ddb():
return boto3.client("dynamodb")
# 大きな辞書は本当に必要になった呼び出し側でだけ作る実測結果
| 実装 | avg import ms |
|---|---|
| 旧(重いトップレベル) | 2475.603 |
| 新(軽いトップレベル + 遅延生成) | 1275.472 |
旧実装ではトップレベルで boto3.client を3つ生成し、15,000件の辞書を構築しています。新実装ではトップレベル処理を実質ゼロに抑え、必要になった時点で lru_cache 付き関数経由でクライアントを取得する形にしています。
実装時の注意点
– 「全 Lambda 共通で使うシングルトン」を Layer のトップレベルで作りたくなりますが、使わない Lambda にも初期化コストを払わせることになります。チームの設計方針などもあると思うので、共通化の際は本当に必要がどうかよく検討しましょう。
– どうしてもトップレベルで初期化したい場合は、その Layer を本当に必要とする Lambda にだけ付ける運用に分けます。
4. S3:不要な HeadObject を省く
課題点
S3 からオブジェクトを取る前に、安全策として head_object で存在確認をしてから download_fileobj で取得する書き方が存在していました。1回の API 呼び出しのつもりが、実際には HEAD と GET で2往復しているため、小さいファイルを大量に読む箇所で差が積み上がっていました。
旧実装:head_object + download_fileobj
def fetch_old(bucket, key):
try:
s3.head_object(Bucket=bucket, Key=key) # 存在確認
except s3.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "404":
return None # 存在しなければ取得しない
raise
buf = io.BytesIO()
s3.download_fileobj(bucket, key, buf)
return buf.getvalue()新実装:get_object のみ
get_object を投げて NoSuchKey で握り潰すか、そもそも上流で存在保証されているなら HEAD は不要です。
def fetch_new(bucket, key):
try:
resp = s3.get_object(Bucket=bucket, Key=key)
except s3.exceptions.NoSuchKey:
return None # 存在しなければ取得しない
return resp["Body"].read()実測結果
同じ小さめのオブジェクトを取得する処理での比較(各7回平均)です。
| 実装 | avg ms | p95 ms |
|---|---|---|
| 旧(head + download_fileobj) | 76.687 | 166.974 |
| 新(get_object のみ) | 31.139 | 37.912 |
改善比は約2.46倍となりました。
1ファイルあたり数十ミリ秒の違いですが、小さいファイルを大量に直列で取りに行く処理ほどこの差が積み上がります。実測値ベースで行くと1ファイルあたり45ミリ秒なので、N=1000であれば約45秒の差につながります。
実装時の注意点
– 存在しないキーに対する挙動が変わります。旧実装は head_object の段階で 404 を踏みますが、新実装は get_object の段階で NoSuchKey が発生します。呼び出し側のエラーハンドリングを揃えておきます。
– 「ファイルが存在しないことが想定内」のフローでは、head_object の方がレスポンス本体を返さない分安いケースもあります。常に GET が正しいわけではなく、実運用での想定を含め、全体を設計する必要があります。
5. Lambdaトップレベルメモ化:設定値の毎回 I/O を止める
課題点
設定値・マスタデータ・機能フラグなどを handler の中で毎回 DynamoDB / SSM Parameter Store / Secrets Manager から取りに行く実装はよく見かけます。warm start でも実行のたびに I/O が走るため、低レイテンシ重視のエンドポイントで無視できないオーバーヘッドとなります。
旧実装:毎回 DynamoDB から取得
def get_config(version):
resp = dynamodb.get_item(
TableName=CONFIG_TABLE,
Key={"pk": {"S": f"CONFIG#{version}"}},
ConsistentRead=True,
)
return resp["Item"]
def handler(event, context):
cfg = get_config("2026-05-24")新実装:トップレベルで lru_cache
from functools import lru_cache
@lru_cache(maxsize=1)
def get_config(version):
resp = dynamodb.get_item(
TableName=CONFIG_TABLE,
Key={"pk": {"S": f"CONFIG#{version}"}},
ConsistentRead=True,
)
return resp["Item"]
def handler(event, context):
cfg = get_config("2026-05-24")同じ Lambda 実行環境(同じ warm sandbox)が生きている間は、最初の1回だけ DynamoDB を叩き、それ以降はキャッシュヒットで返します。
実測結果
1 Invoke 内でキャッシュをクリアした上で、同じ get_config を7回連続呼び出した平均です。
| 実装 | avg ms | min ms | p50 ms |
|---|---|---|---|
| 旧(毎回 DynamoDB) | 32.196 | 3.541 | 19.866 |
| 新(lru_cache) | 18.453 | 0.001 | 0.002 |
平均だけ見ると約1.7倍にとどまりますが、これは新実装の「1回目のミスが約129ms 出た」のが平均を引き上げているためで、実態は以下のような分布になります。
| 回数 | 新実装 duration_ms |
|---|---|
| 1 | 129.159 |
| 2 | 0.005 |
| 3 | 0.002 |
| 4 | 0.001 |
| 5 | 0.002 |
| 6 | 0.001 |
| 7 | 0.001 |
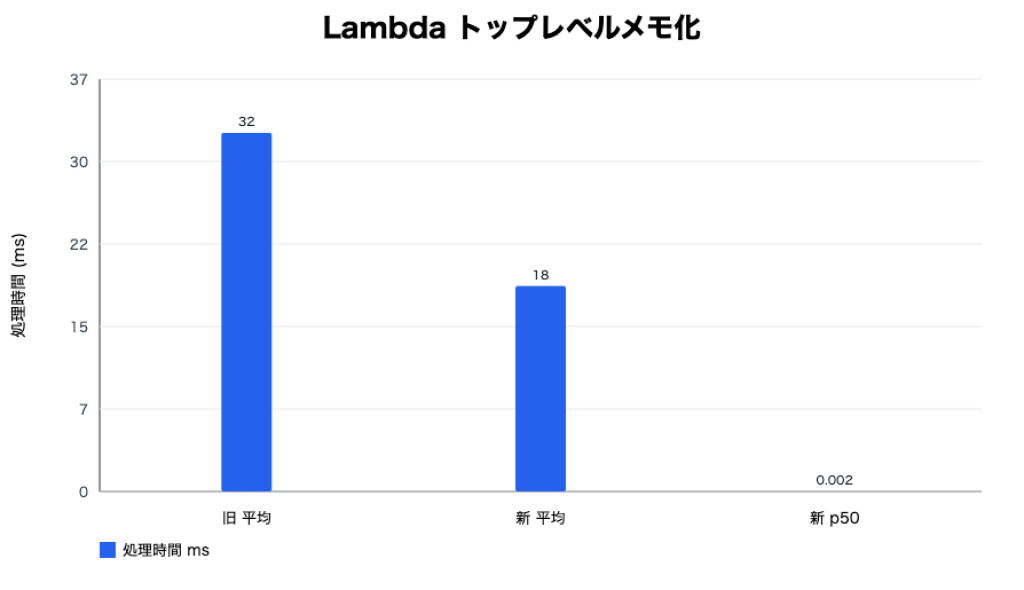
平均で見るよりは、初回実行とそれ以降という見方をするのが適切です。warm な Lambda 実行環境が長く生きるエンドポイントほど、累積効果は大きくなります。
実装時の注意点
– メモ化対象は「同じ実行環境内で同じ結果を返してよい値」に限定します。ユーザーごとに変わる値や、即時反映が必要な機能フラグをメモ化すると、当然ながら反映遅延を生みます。キャッシュ化して良い値かどうかは慎重に検討する必要があります。
– TTL が必要であれば cachetools.TTLCache 等を使うか、外部から明示的にキャッシュを破棄する経路(バージョンキーを切り替えるなど)を設計しておきます。
– Lambda 実行環境は数分~数時間で再利用が止まります。「いつかは再ロードされる」前提のキャッシュとして扱うのが安全です。
まとめ
本記事では、Lambda 上の Python 処理について、DynamoDB の並列取得、RDS のトランザクションスコープ最小化、Lambda Layer のトップレベル軽量化、S3 アクセスパターンの見直し、トップレベルメモ化という5つの改善を取り上げました。
どの改善もコード量としては数行から十数行で済みますが、実装次第で数倍から数十倍の高速化が見込めます。
DynamoDB の並列化について、当初は「ThreadPoolExecutor を導入すれば速くなる」と単純に考えていました。しかし実際には、低メモリ設定の Lambda ではむしろ逐次処理より遅くなるという結果に直面しました。
性能改善に着手する前は、Lambda のメモリ設定によって外部 IO と Lambda のコンピューティング能力のどちらがボトルネックになりうるか、という感覚を持っていませんでした。そのため、ThreadPoolExecutor で並列取得を行う際の適切なメモリ設定を理解できていなかったのです。
その後 X-Ray やログを確認したところ、ロジック上は並列取得になっているものの、Lambda の処理能力が追いつかず、実質的には逐次処理に近い状態になっていたことがわかりました。この気づきから、ロジックの改善だけでなく Lambda の設定も含めて処理を最適化することができました。
今回のベンチマークは対象処理のみの計測のため、実際の案件で同じ高速化倍率が得られるとは限りませんが、CloudWatch・X-Ray・OpenTelemetry などで処理遅延の原因と支配的な要因を理解することが適切な高速化・効率化に繋がります。
本記事の内容で適用できそうなものがあればぜひ適用して処理時間、コストの最適化を行ってみてください。
投稿者プロフィール

- AWSをメインとするバックエンドエンジニア。要件定義から運用保守まで幅広く対応しています。趣味は競技プログラミングで、アルゴリズムやロジックのパフォーマンスチューニングが得意。