

はじめに
クラウドベースのデータ連携ツールであるDataSpider Cloud は、汎用的に活用できるCSVファイルにSalesforce から取得したレコードを出力して、データ変換、Excel やAWSなどの他サービスへのデータ連携が可能です。
今回は、「Bulkデータ読み取り(QUERY)」ツールを使用した実装イメージをご紹介します。「Bulkデータ読み取り(QUERY)」ツールはSalesforce のBulk API を使用し、非同期処理の大量データ取得が可能なツールです。
本記事では既にDataspider Cloud を導入済で、Salesforce のデータ連携を始めよう!という方へ向けた技術紹介記事となります。
スクリプト作成手順
[Bulkデータ読み取り(QUERY)]アイコンの設定
DataSpider のデザイナ画面で、ツールパレットから[クラウド]>[Salesforce Bulk]>[Bulkデータ読み取り(QUERY)] のアイコンをドラッグ&ドロップでキャンパスに配置します。
アイコンの設定画面で、以下①~③の必須項目を設定します。
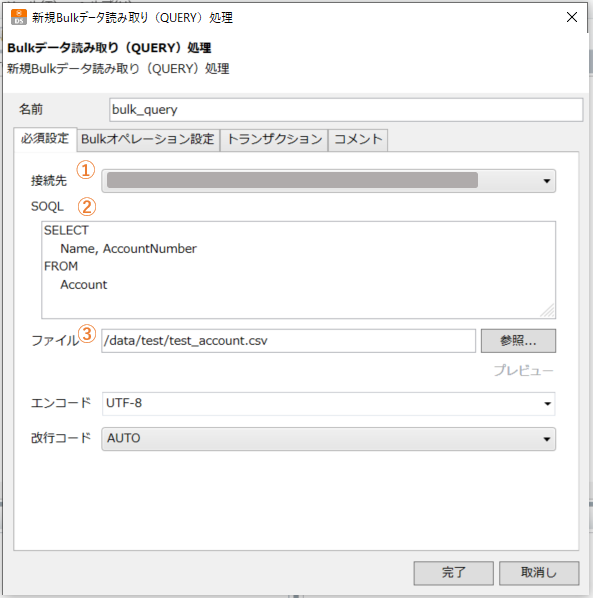
①接続先の設定
接続先は、グローバルリソースと呼ばれるDataSpider とSalesforce 組織への接続設定を選択します。
詳細な手順はこちらのブログ記事で紹介していますので、参考にしてください。
②SOQLの設定
レコードを取得するSOQL を記載します。
今回は以下のように、Salesforce標準の取引先オブジェクトより「取引先名」と「取引先番号」を取得するSOQL とします。
SELECT
Name, AccountNumber
FROM
Account
③ファイルを指定
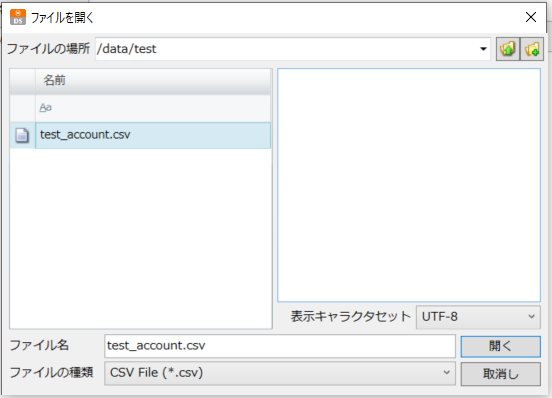
SQOLで取得したレコードを保存するCSVファイルを指定します。
DataSpider Cloud の「エクスプローラ」で確認できるフォルダ階層を指定し、任意のファイル名を設定します。
「完了」ボタンを押下することで、レコードを取得するアイコンの設定が完了します。
「Bulkデータ読み取り(QUERY)」アイコンの後続処理に、以下のように「CSVファイル読み取り」アイコンと「マッピング」アイコンを追加することで、上記で取得したCSVファイルのデータを出力データへ、項目ごとの紐づけ設定ができます。
[CSVファイル読み取り] アイコンの設定例
ツールパレットより[ファイル]>[CSV]>[CSVファイル読み取り]のアイコンをドラッグ&ドロップでキャンパスに配置します。
アイコンの設定画面で、以下①~②の必須項目を設定します。
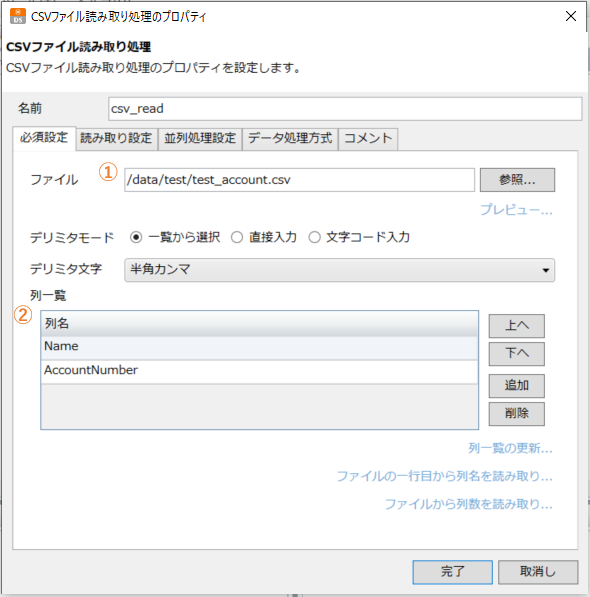
①ファイル設定
「Bulkデータ読み取り(QUERY)」アイコンで設定した出力先ファイルを指定します。
②列一覧
CSVファイル内の列名一覧を確認します。「列一覧の更新…」リンクを押下することで表示の最新化ができます。
[マッピング] アイコンの設定例
ツールパレットより[変換]>[基本]>[マッピング] のアイコンをドラッグ&ドロップでキャンパスに配置します。
アイコンの設定画面で、以下①~②の必須項目を設定します。
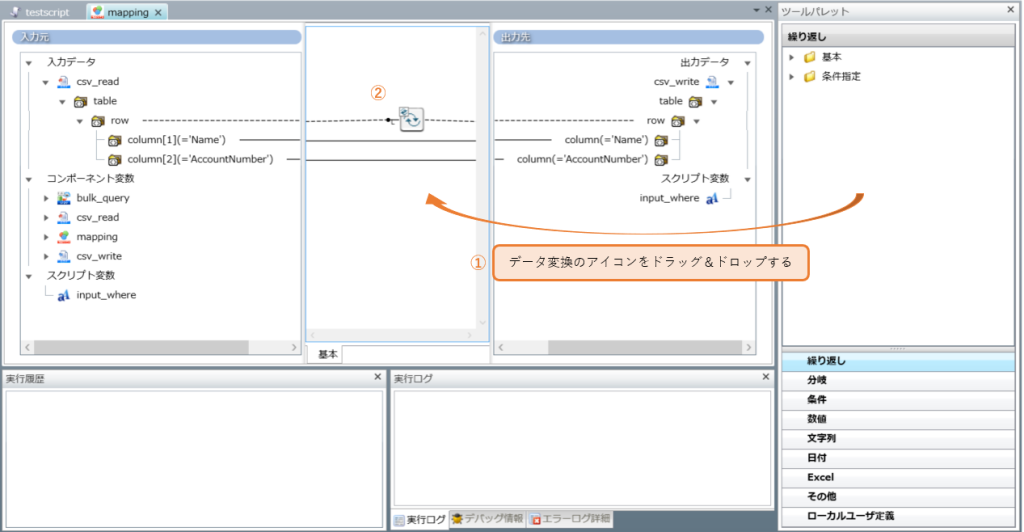
①データ変換
ツールパレットよりデータを変換するアイコンを追加して、項目値の変換処理を追加します。
②出力データへの紐づけ
ドラッグ&ドロップ操作で、入力データと出力データを項目単位で紐づけを設定します。
※取得データを他サービスへ連携したい場合は、「マッピング」を作成前に、他サービスへの書き込みを行うアイコンをキャンバス内に配置することで、出力先欄で選択が可能となります。他サービスへの書き込みアイコンの設定は、また別の機会にご紹介したいと思います。
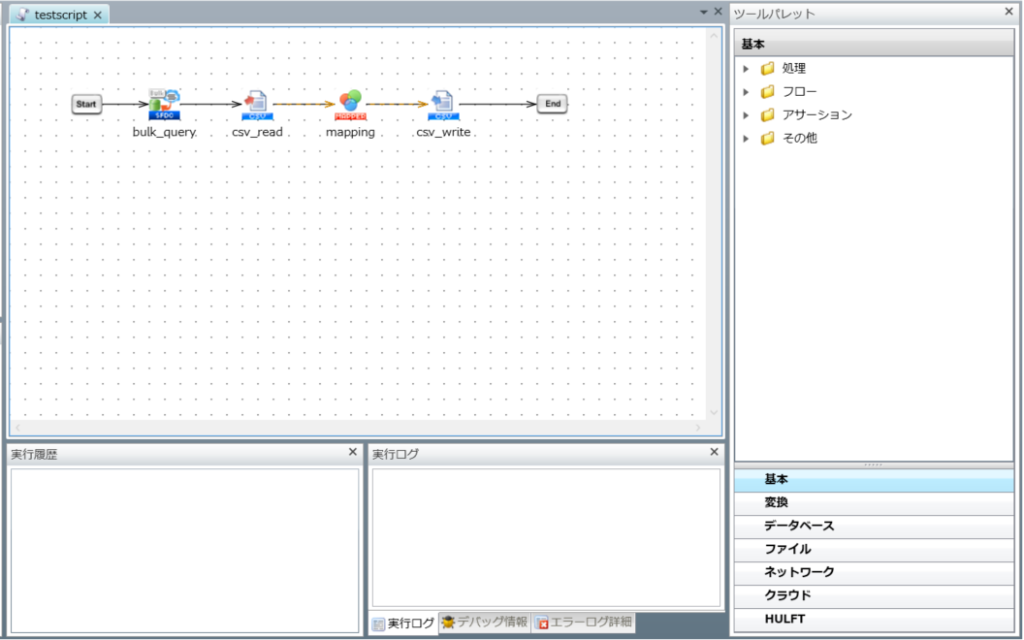
[Start] から[End] まで各アイコンをフローで繋ぎ、スクリプトを保存します。
スクリプト変数を活用したデータの柔軟な取得方法
Dataspider Cloud では、スクリプト変数に固定値を設定し、スクリプト内の各アイコンの設定に利用できます。スクリプトを実行するトリガーの引数でスクリプト変数の値を設定し、SOQL のWHERE 句として利用することで、トリガーを実行する度に取得するデータを柔軟に変更することができます。
以下、活用例をご紹介します。
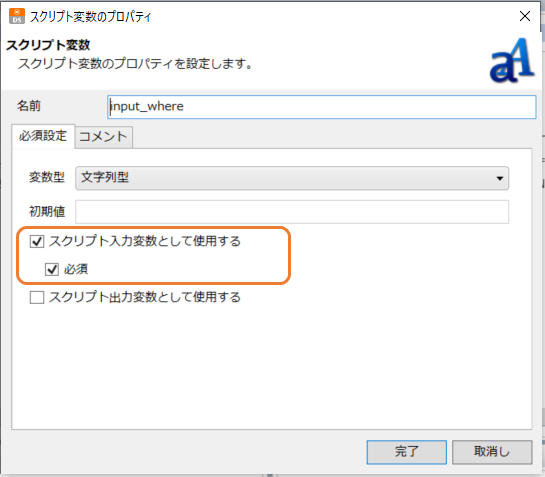
スクリプトにスクリプト変数を新規追加し、「スクリプト入力変数として使用する」にチェックを付けます。そして、以下のようにSOQLの絞込条件としてスクリプト変数を挿入します。
SELECT
Name, AccountNumber
FROM
Account
${input_where}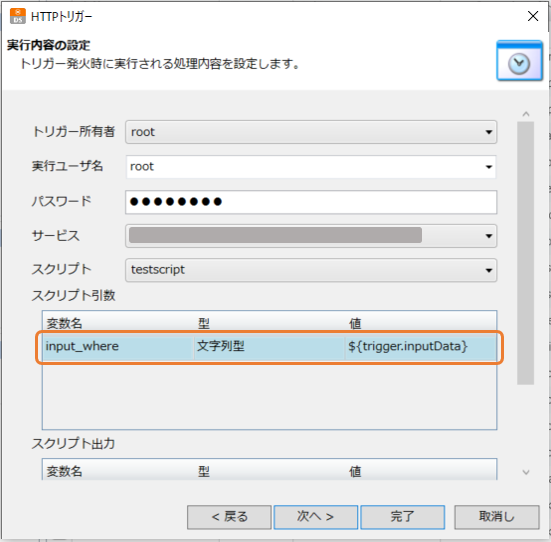
スクリプトを実行するトリガーの設定で、スクリプト引数には「${trigger.inputData}」と設定します。
これで、トリガー実行時のINPUTに応じて、取得するレコードをカスタマイズできるようになりました。
さらに、Salesforce のApexクラス内で、HTTPトリガーを実行する記入例をご紹介します。パラメータ情報を設定する際に、上記で設定した入力変数に「WHERE 条件1 AND 条件2」と入力し、HTTPトリガーを実行します。ここで注意したいのが、HTTPトリガー実行は、URL型でのリクエスト送信となるため、INPUTに日本語が含まれるとエラーが発生することです。INPUTで送信するWHERE句の内容は、レコードIDを絞込条件とすることをお勧めします。
public class calloutHTTP {
@Future(callout=true)
public static void calloutHTTP() {
//HTTPリクエストの作成
HttpRequest httpreq = new HttpRequest();
//要求のエンドポイントを指定(実行URL+パラメータ情報)
httpreq.setEndpoint(【HTTPトリガー実行URL】 + '&inputwhere=' + EncodingUtil.urlEncode(' WHERE Id=\'xxxxx1\' AND Id=\'xxxxx2\'', 'UTF-8'));
//要求ヘッダーの内容を設定(認証ID+認証パスワード)
httpreq.setHeader('Authorization', 'Basic ' + EncodingUtil.base64Encode(Blob.valueOf(【HTTPトリガーのBASIC認証ID】 + ':' + 【HTTPトリガーのBASIC認証パスワード】)));
//メソッドの種類を設定
httpreq.setMethod('POST');
//要求のタイムアウトを設定
httpreq.setTimeout(120000);
// HTTPリクエストの送信
Http httpres = new Http();
httpres.send(httpreq);
}
}

実際に実行してみると、Salesforce より約7万件のレコードを取得して2.8MBのCSVファイルを出力する場合、「Bulkデータ読み取り(QUERY)」の実行に4.43秒かかることが確認できます。
おわりに
DataSpider Cloud での「Bulkデータ読み取り(QUERY)」ツールを使用した実装イメージをご紹介させていただきました。データ連携の一つの方策がご理解いただけたかと思います。
上記でご紹介したスクリプト変数活用方法が、より柔軟にDataspider Cloudを使用するための一つのヒントになれば幸いです。
他にも様々な機能がありますので、またご紹介させていただけたらと思います。
投稿者プロフィール

-
2020年頃よりSalesforce の学習を始めました。
Apex によるバックエンド処理や、Visualforce 画面などを用いた開発業務を行っています。
日々進化するSalesforce での開発における、便利な方法を皆さまと共有できればと思います。
最新の投稿
 Salesforce2025.01.23【Salesforce】ユーザーを無効化する時に注意すべきポイント2つを紹介
Salesforce2025.01.23【Salesforce】ユーザーを無効化する時に注意すべきポイント2つを紹介 Salesforce2024.07.01【Salesforce】注意!CSV出力時のデータ型ごとの出力形式の違い
Salesforce2024.07.01【Salesforce】注意!CSV出力時のデータ型ごとの出力形式の違い Salesforce2024.01.19【Salesforce】非同期処理の大量のデータを他システムへ連携するためのDataspider Cloud 活用例
Salesforce2024.01.19【Salesforce】非同期処理の大量のデータを他システムへ連携するためのDataspider Cloud 活用例 Salesforce2023.05.24【Salesforce】Apex処理のガバナ制限におけるヒープサイズ制限による「System.LimitException: Batchable instance is too big」エラーの回避方法について
Salesforce2023.05.24【Salesforce】Apex処理のガバナ制限におけるヒープサイズ制限による「System.LimitException: Batchable instance is too big」エラーの回避方法について