プロジェクトリーダーという役割上、主体となって開発作業を行うことは殆どないのですが、
SAP HANA Cloud(以降 SAP HANAと表記)で、階層データ作成の検証を行う機会がありました。
所感ですが手軽さとパフォーマンスに感動。今回はその件について紹介します。
【参考】SAP HANAとは?
夜間バッチを使わない階層データを作成・取得方法を検証
今回私が検証したかったのはSAP HANAの環境で、労力をかけず階層データを作成・取得する方法です。
階層データの取り扱いは業務システムでは定番で、例えば過去に担当していた製造業の生産系システムではBOM(Bill Of Materials)、いわゆる部品表が一番身近な階層データでした。
製品を構成する部品は膨大な量となりますので、夜間バッチなどで品目テーブルから階層データ(部品表)を事前に作成し、日中のオンラインでアクセスするといったことが殆どです。
ですが今回は夜間バッチではなく、日中のオンラインでリアルタイムに階層データを作成・取得する仕組みが必要でした。

一番初めに思いつくのが常套手段として、下記のようなCTE(Common Table Expressions)で、WITH句を使った共通テーブル式です。
WITH recursive temp (n, fact) AS
(
SELECT 0, 1
UNION ALL
SELECT n + 1, ( n + 1) * fact
FROM temp
WHERE n < 9
)
SELECT * FROM temp;
再帰的に問い合わせて階層を作るのですが、SAP HANAでは以下のエラーが発生してしまいました。
SQLエラー [259] [HY000]: SAP DBTech JDBC: [259] : invalid table name: Could not find table/view
調べてみると、公式ドキュメントでは「データセット内の再帰的な関係を表現する手段として、WITH RECURSIVE 共通テーブル式を提供します」と記述されていましたが、
反対に「HANAは再帰クエリ式をサポートできません」としているサイトもありました。

HANA DBでの階層データ作成について
公式ドキュメントをさらに読むと、
”データ セット内の再帰的な関係を表現する手段として、WITH RECURSIVE 共通テーブル式を提供します。おそらく、WITH RECURSIVE の実際の使用の大部分は SAP HANA の階層関数でカバーできますが・・・”とありました。つまり、SAP HANAでは階層にかかわる関数が標準で用意されているということです。
「そういえば過去に触ったSACやDWCも階層を用いた分析やモデル作成ができたな。基盤はHANA DBだったし。」と思い出し、さっそくSAP HANAの階層関数(HIERARCHY Function)を使って実際に階層データが作成できるか確認してみました。
まずはテストデータの準備として、所属ID・所属名・親所属IDの3列からなる簡単な組織データを準備しました。
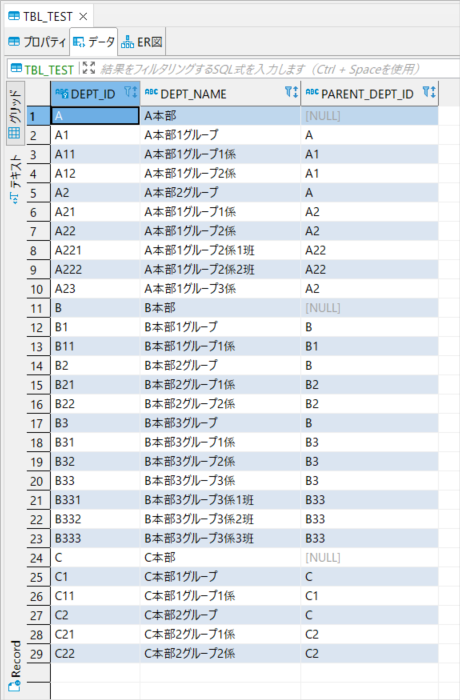
この組織データに対して階層データを作成するSQLを実行します。
ID(DEPT_CODE)と親ID(PARENT_DEPT_CODE)の列名を、それぞれNODE_ID・PARENT_IDとすることで階層関数が動作します。
SELECT
HIERARCHY_RANK,
HIERARCHY_TREE_SIZE,
HIERARCHY_PARENT_RANK,
HIERARCHY_LEVEL,
HIERARCHY_IS_CYCLE,
HIERARCHY_IS_ORPHAN,
NODE_ID,
DEPT_NAME,
PARENT_ID
FROM HIERARCHY (
SOURCE (
SELECT
DEPT_ID AS NODE_ID,
DEPT_NAME,
PARENT_DEPT_ID AS PARENT_ID
FROM TBL_TEST
)
) ORDER BY HIERARCHY_RANK;
実行後、以下の結果が取得できます。
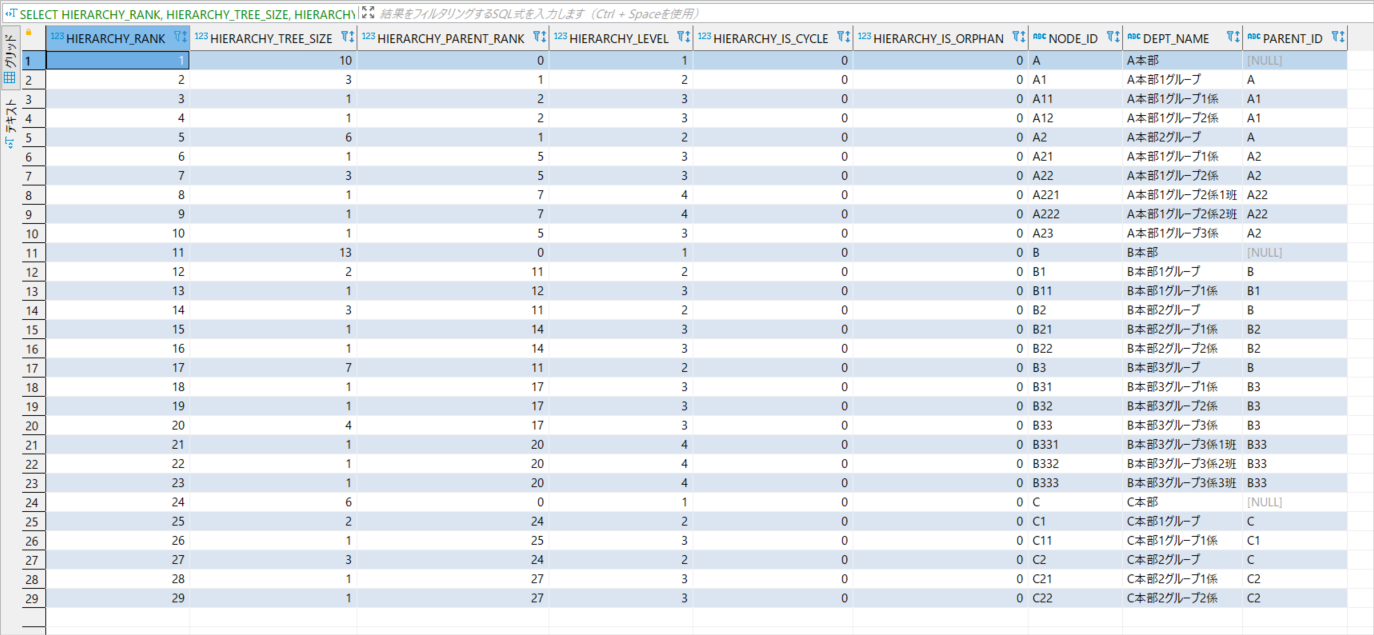
簡単に階層データを作成できました。
各項目値の意味は以下になります。
| 列 | 意味 |
|---|---|
| hierarchy_rank | 連続した要素番号 |
| hierarchy_tree_size | 自身の配下に存在する子要素数 |
| hierarchy_parent_rank | 親要素の要素番号 |
| hierarchy_level | 自身が何階層目に属しているか |
| hierarchy_is_cycle | 自身が循環しているか |
| hierarchy_is_orphan | 自身が孤立しているか |
更にこの結果をビューにしておけば、
他の階層関数を組み合わせてパス情報を付加することもできます。
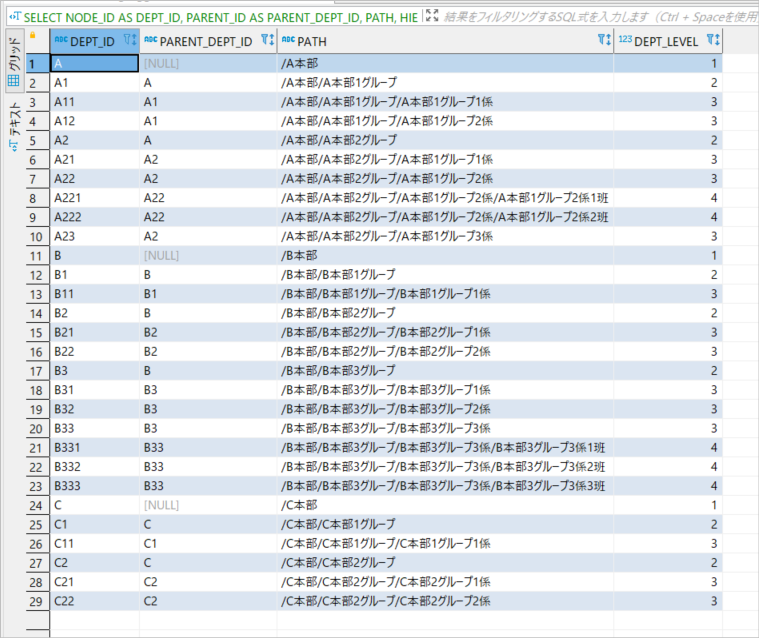
先程実行したSQLをそのまま使って「V_HIERARCHY_TEST」というビューを作成しておき、下記のSQLを実行します。
SELECT
NODE_ID AS DEPT_ID,
PARENT_ID AS PARENT_DEPT_ID,
PATH,
HIERARCHY_LEVEL AS DEPT_LEVEL
FROM (
SELECT
HIERARCHY_LEVEL,
NODE_ID,
PARENT_ID,
‘/’ || PATH AS PATH
FROM HIERARCHY_ANCESTORS_AGGREGATE (
SOURCE V_HIERARCHY_TEST
MEASURES ( string_agg (DEPT_NAME, ‘/’ ) AS PATH ) )
ORDER BY NODE_ID
);
PATH列にて所属名をスラッシュで繋げることができました。
こちらも簡単ですね。
その他諸々の検証後、正規に開発した機能では、3万件程度とそこまで多くないデータ量とはいえ、
他テーブルや自身と結合した状態でもレスポンスに気を使うことはなく、非常に使いやすい階層データとなりました。
階層関数のパフォーマンスについて
インメモリデータベースであるHANA DBとMySQLを比較とすること自体ナンセンスではありますが、
大量データを使って、階層データの取得時間も確認してみました。
(MySQL側はWITH句を使ったCTEで処理)
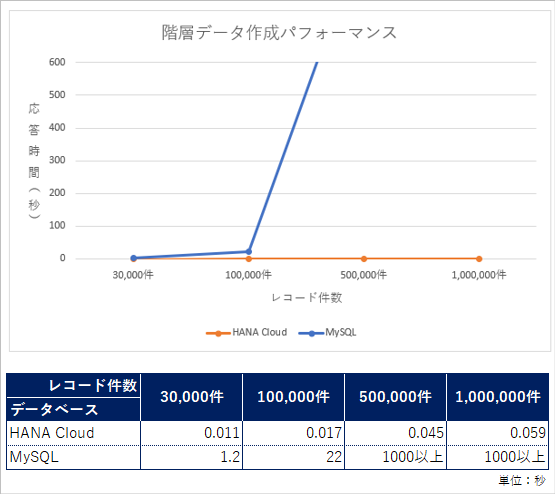
MySQLはレコード件数が50万を超えると、15分経過してもレスポンスが無いにも関わらず、
HANA DBは100万件であろうが1秒を切るという結果になりました。
想定していた以上に速いです…。
複雑な構成で深い階層の大量データを扱う事案が発生した場合、改めて検証は必要ですが、このパフォーマンスはとても魅力的です。
最後に
WITH句を使った階層データ作成の試行がきっかけで、HANA DBの階層関数の存在を知ることができました。
階層関数は扱いに慣れれば、複雑なSQLを作成する手間も省け、積極的に使える機能だと感じましたし、とくにパフォーマンスに関しては「一度使ってみて!」と言いたくなるレベルです。
ちなみに階層関数はSAP HANAのコア機能として、様々な場面での利用を想定して、専用の開発ガイドも用意されています。(検証作業もこちらを参考に行いました)
【参考】 SAP HANA Hierarchy Developer Guide
今回はSAP HANAの一部分にしか触れていませんが、公式ページにあるように、
「できない事はないんじゃないの?」と思わされるほど様々な機能を備えています。
久しぶりに製品・機能の技術検証を行いましたが、やっぱり楽しいですね。
それではまた。
投稿者プロフィール

-
2004年入社。
汎用機運用から始まり、クラサバ・Webシステムの開発を経験。
2022年4月からSAP Business Technology Platform(SAP BTP)を基盤としたWEB開発業務のリーダーを担当しています。